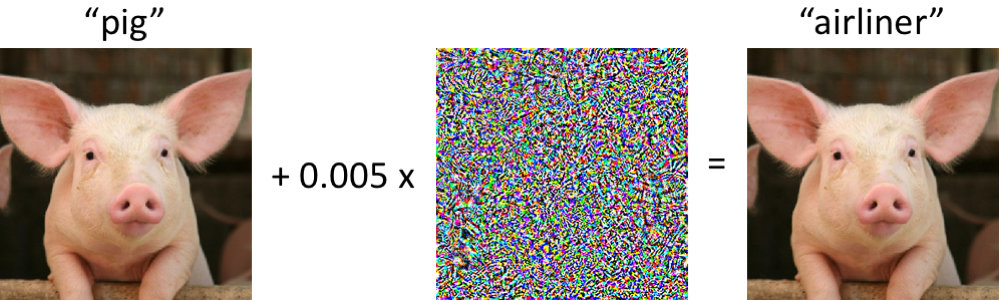DeepSeek-AI. 2025.
“DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” January 22.
https://arxiv.org/abs/2501.12948.
Jaech, Aaron, Adam Kalai, Adam Lerer, et al. 2024.
“OpenAI O1 System Card.” OpenAI, December 21.
https://arxiv.org/abs/2412.16720.
Lambert, Nathan, Jacob Morrison, Valentina Pyatkin, et al. 2024.
“Tülu 3: Pushing Frontiers in Open Language Model Post-Training.” November 22.
https://arxiv.org/abs/2411.15124.
Mądry, Aleksander, and Ludwig Schmidt. 2018.
“A Brief Introduction to Adversarial Examples.” Gradient Science (MIT MadryLab), July 6.
https://gradientscience.org/intro_adversarial/.
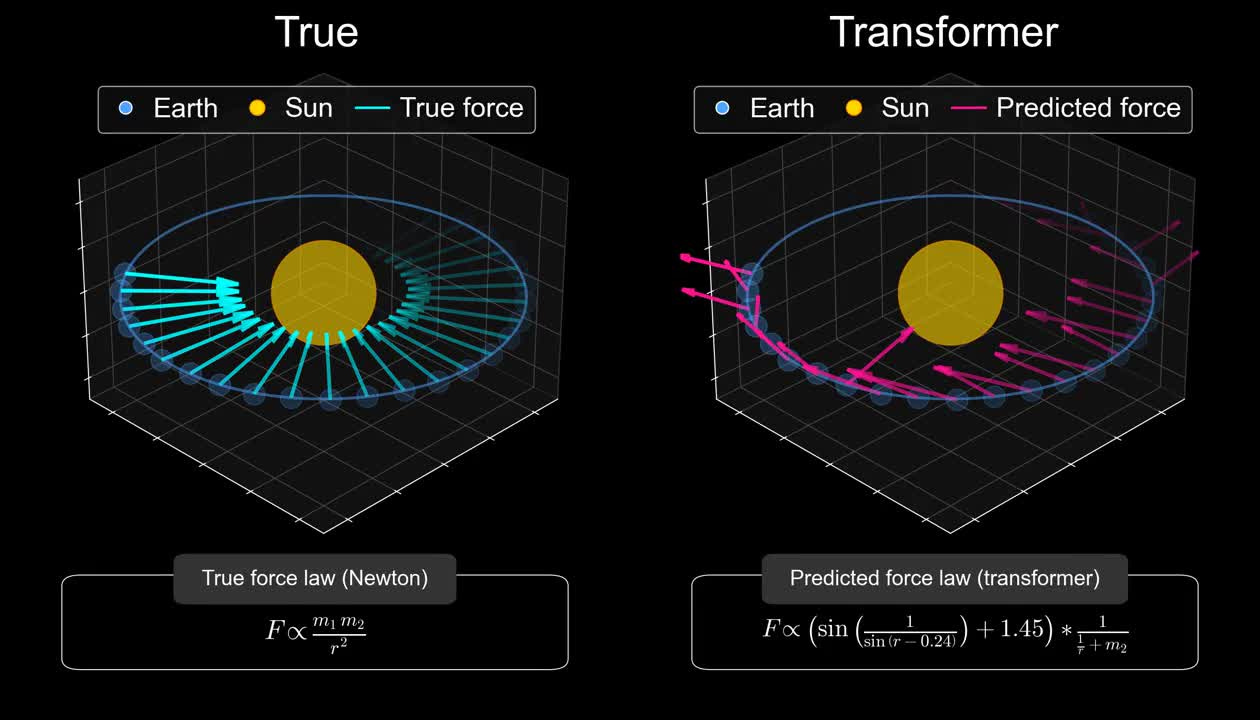
Vafa, Keyon, Peter G. Chang, Ashesh Rambachan, and Sendhil Mullainathan. 2025.
“What Has a Foundation Model Found? Using Inductive Bias to Probe for World Models.” Proceedings of the 42nd International Conference on Machine Learning,
ICML.
https://proceedings.mlr.press/v267/vafa25a.html.
Wei, Jason, Xuezhi Wang, Dale Schuurmans, et al. 2022.
“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” Advances in Neural Information Processing Systems 35.
https://arxiv.org/abs/2201.11903.
Zech, John R., Marcus A. Badgeley, Manway Liu, Anthony B. Costa, Joseph J. Titano, and Eric Karl Oermann. 2018.
“Variable Generalization Performance of a Deep Learning Model to Detect Pneumonia in Chest Radiographs: A Cross-Sectional Study.” PLoS Medicine 15 (11): e1002683.
https://doi.org/10.1371/journal.pmed.1002683.