
[1] "dog_breeds.csv" "dog_events.csv" "dog_inventory.csv" "dog_sales.csv" 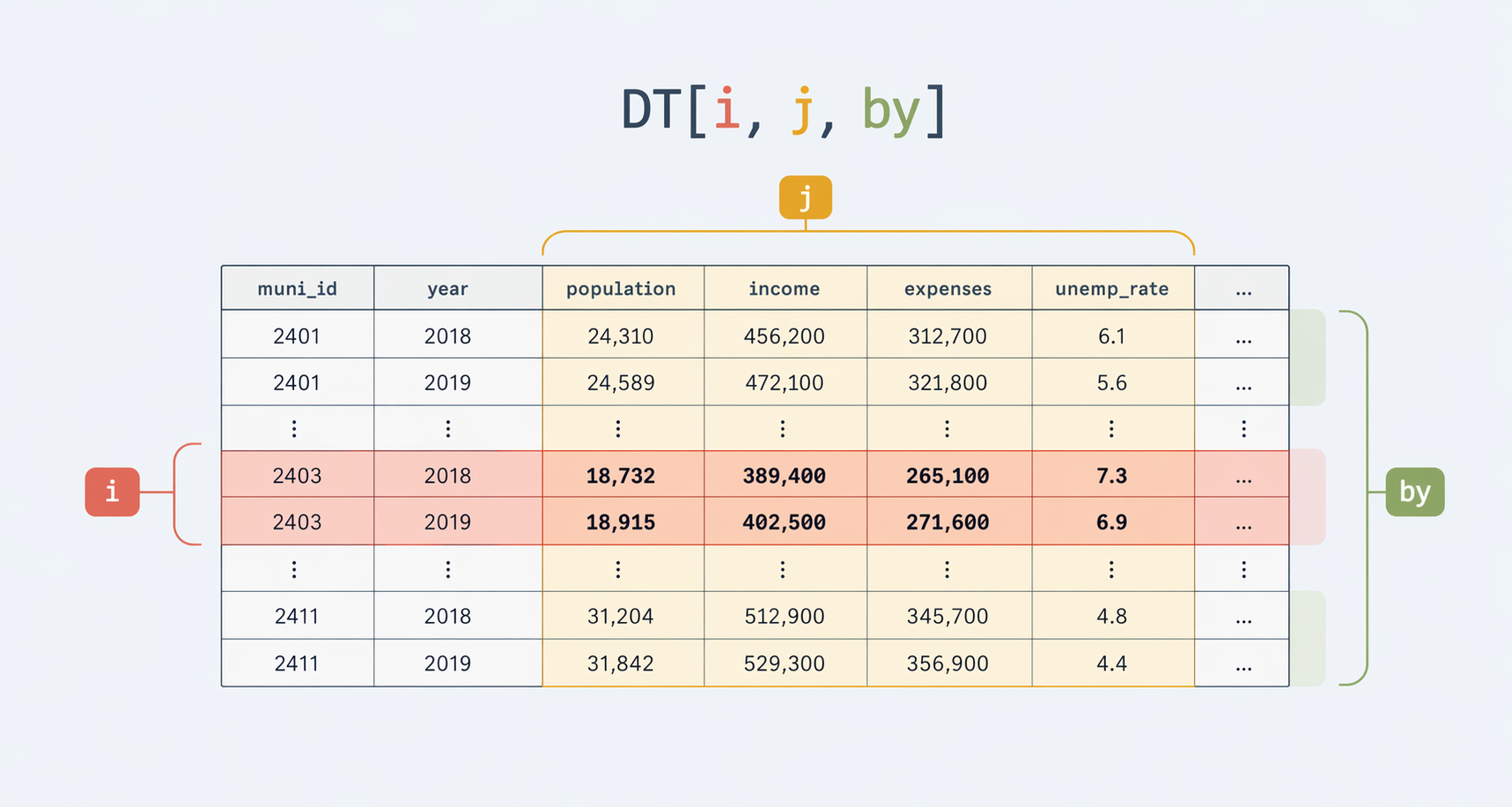
Main takeaways
- A successful import is not the same as a correct import
- Inspect names, types, keys, and missingness immediately
- Read
DT[i, j, by]as “i=rows, j=columns/calculations, by=groups” - Use
:=deliberately andcopy()when you need separation