| N | mean | SD | |
|---|---|---|---|
| x1 | 11 | 9.00 | 3.32 |
| x2 | 11 | 9.00 | 3.32 |
| x3 | 11 | 9.00 | 3.32 |
| x4 | 11 | 9.00 | 3.32 |
| y1 | 11 | 7.50 | 2.03 |
| y2 | 11 | 7.50 | 2.03 |
| y3 | 11 | 7.50 | 2.03 |
| y4 | 11 | 7.50 | 2.03 |
Lecture 10: Visualization and Communication
Adam Altmejd 
The Institute for Evaluation of Labour Market and Education Policy (IFAU)
2026-05-28
Snow’s cholera map
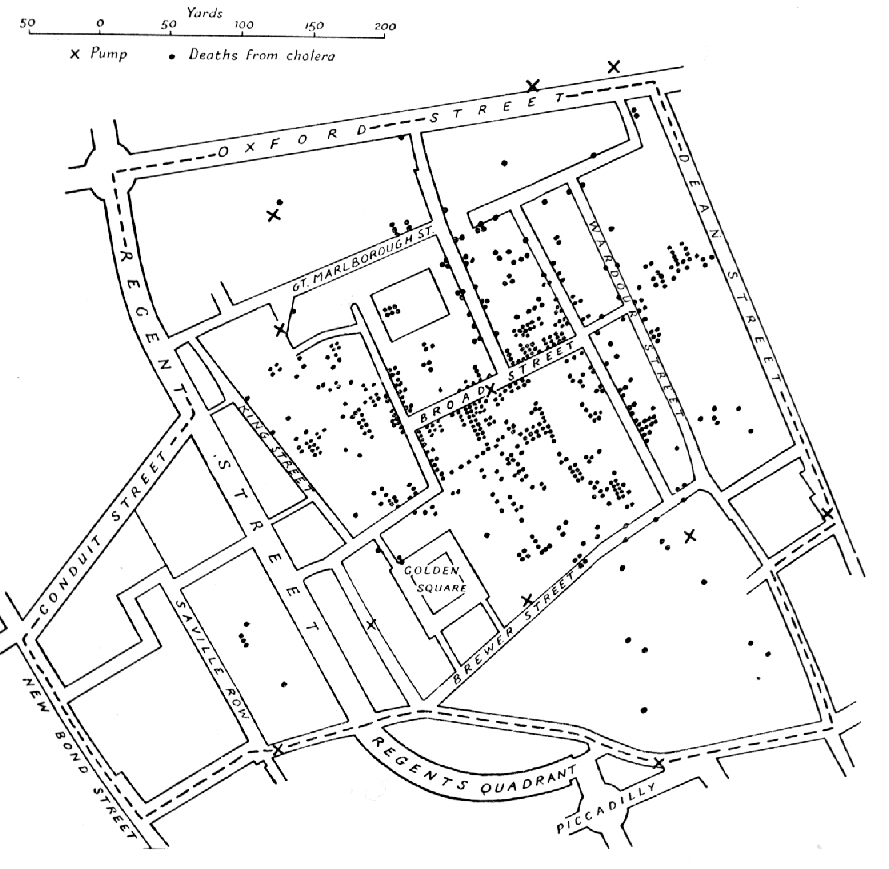
Snow (1855)
Anscombe’s quartet
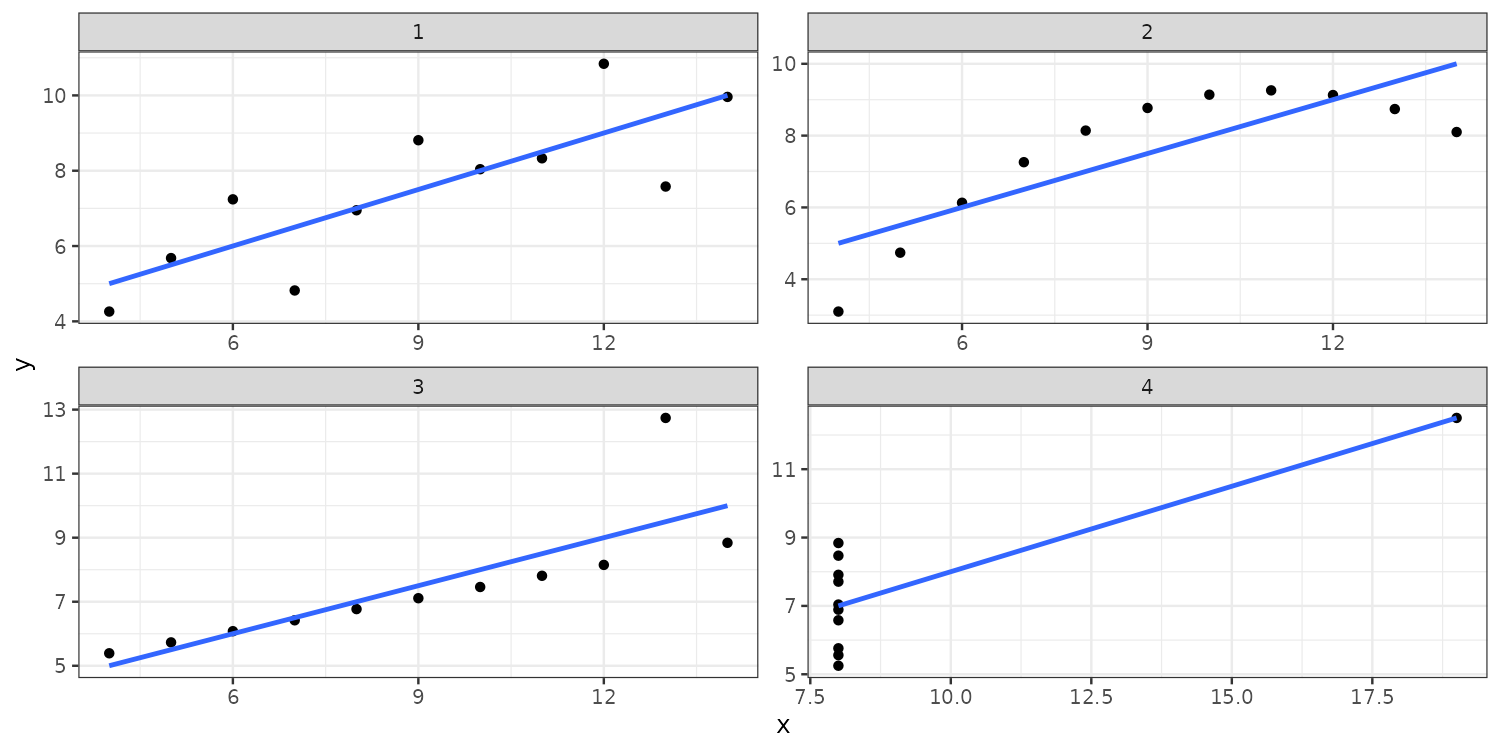
Anscombe (1973)
Summary statistics hide patterns
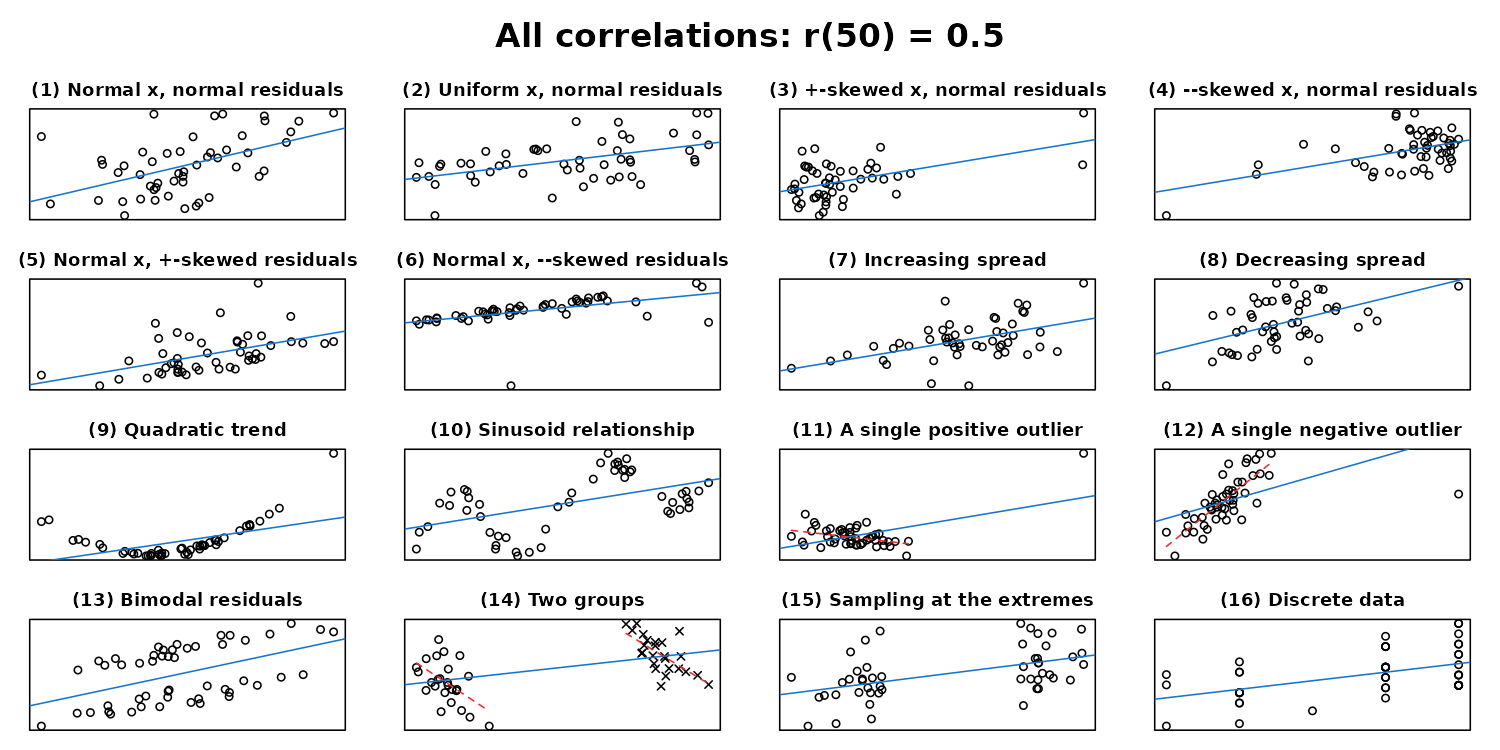
Datasaurus: same stats, different shapes

Matejka and Fitzmaurice (2017)
Wrangling ↔︎ Visualization
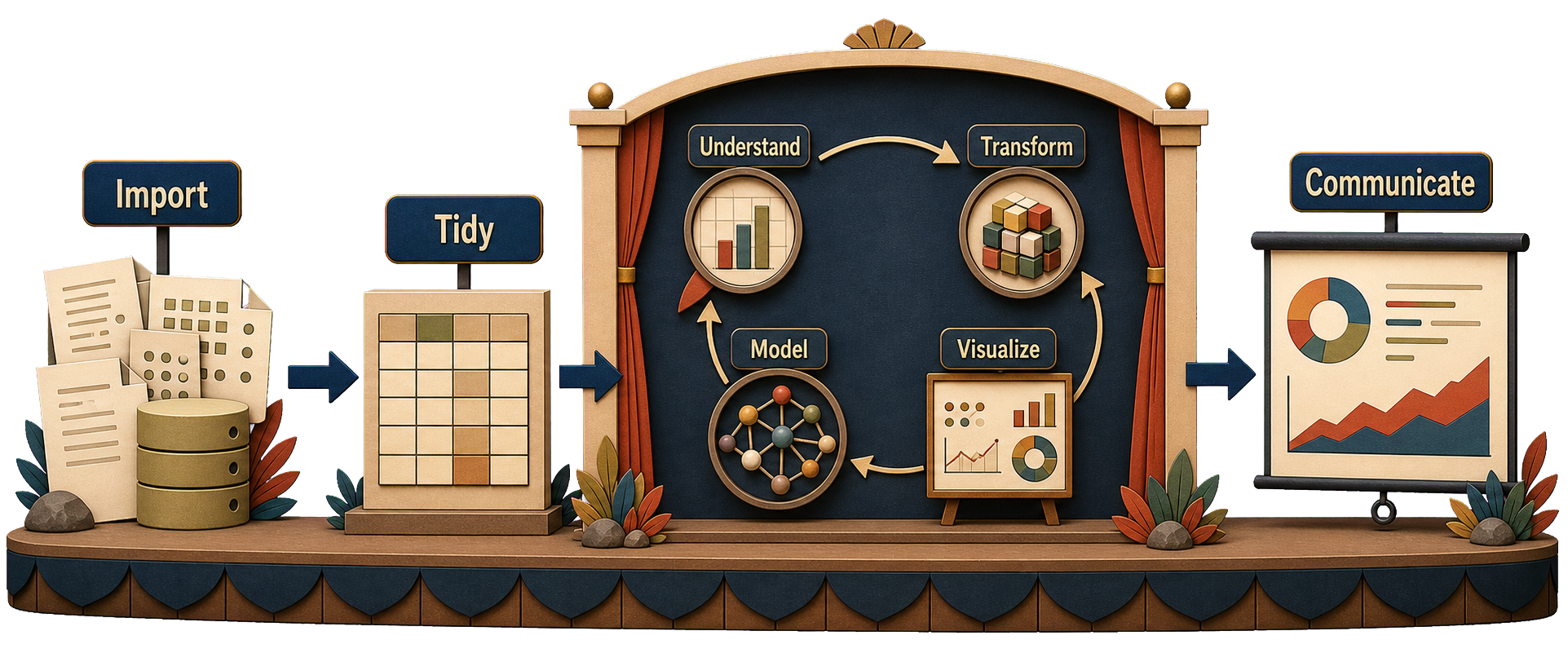
Workflow adapted from Wickham et al. (2023)
Charles Minard’s Infographic of Napoleon’s Invasion of Russia (1869)

Tufte (1983)
Bad graphs: Pandemic TV edition
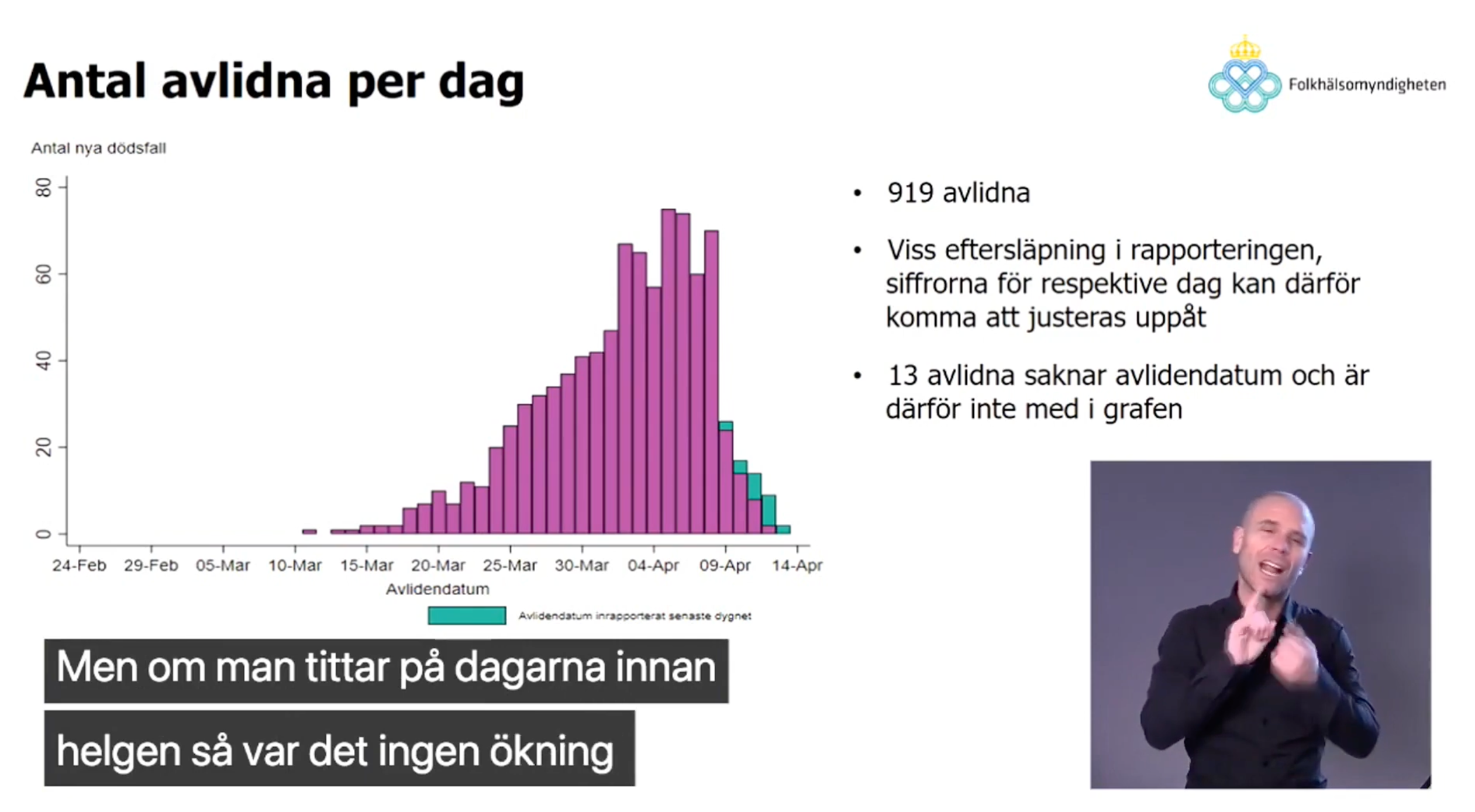
Let’s plot the FOHM data ourselves
fohm_dt <- fread(here("lectures", "lecture_10", "fohm_c19_death_data.csv"))[!is.na(date)]
ggplot(data = fohm_dt[publication_date == "2020-04-13"],
aes(x = date, y = N)) +
geom_col() + scale_x_date() +
geom_vline(xintercept = as.Date("2020-04-08")) + geom_hline(yintercept = 70) +
coord_cartesian(xlim = as.Date(c("2020-03-01", "2020-04-30")), ylim = c(0, 120)) +
labs(title = "Publication date: 2020-04-13", x = NULL, y = "Deaths")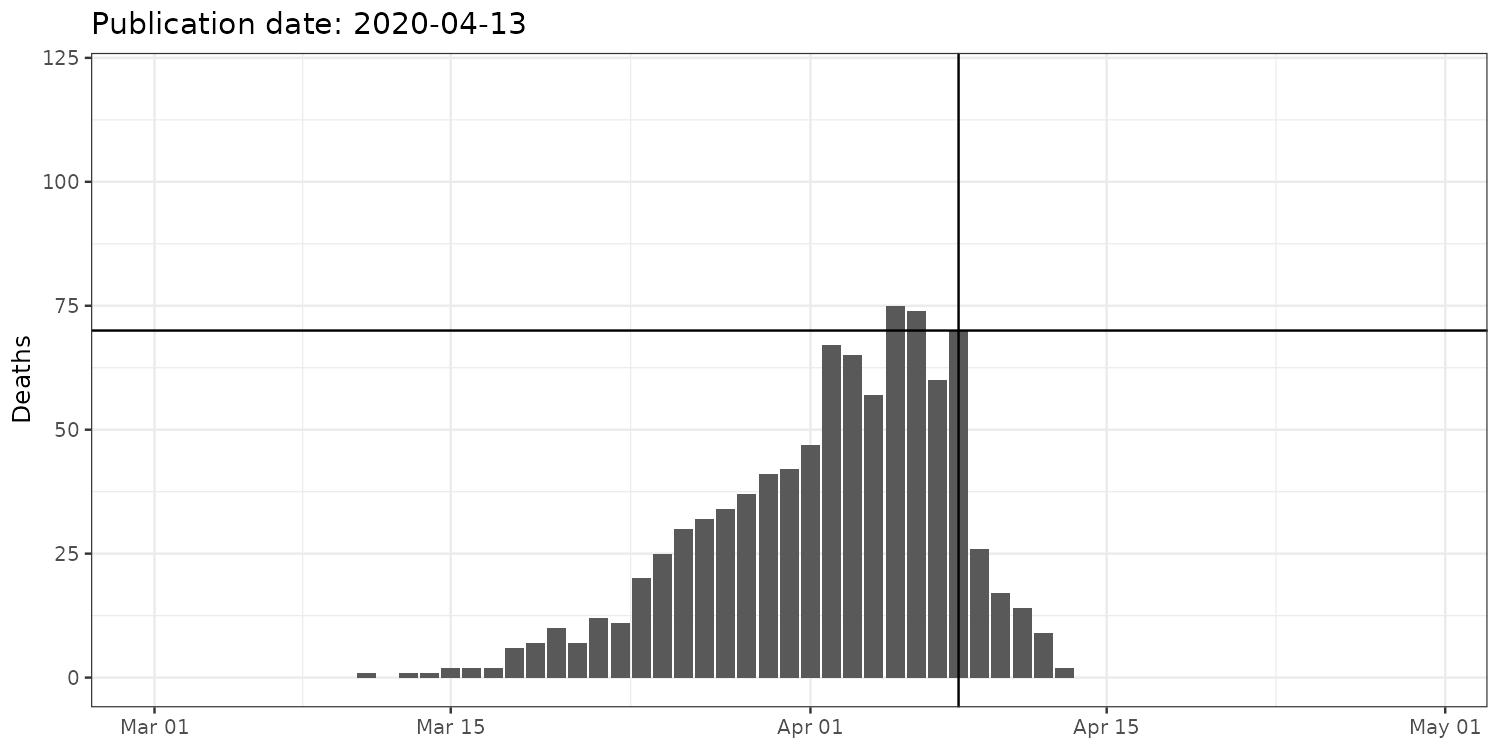
Same lesson, course data: spaghetti
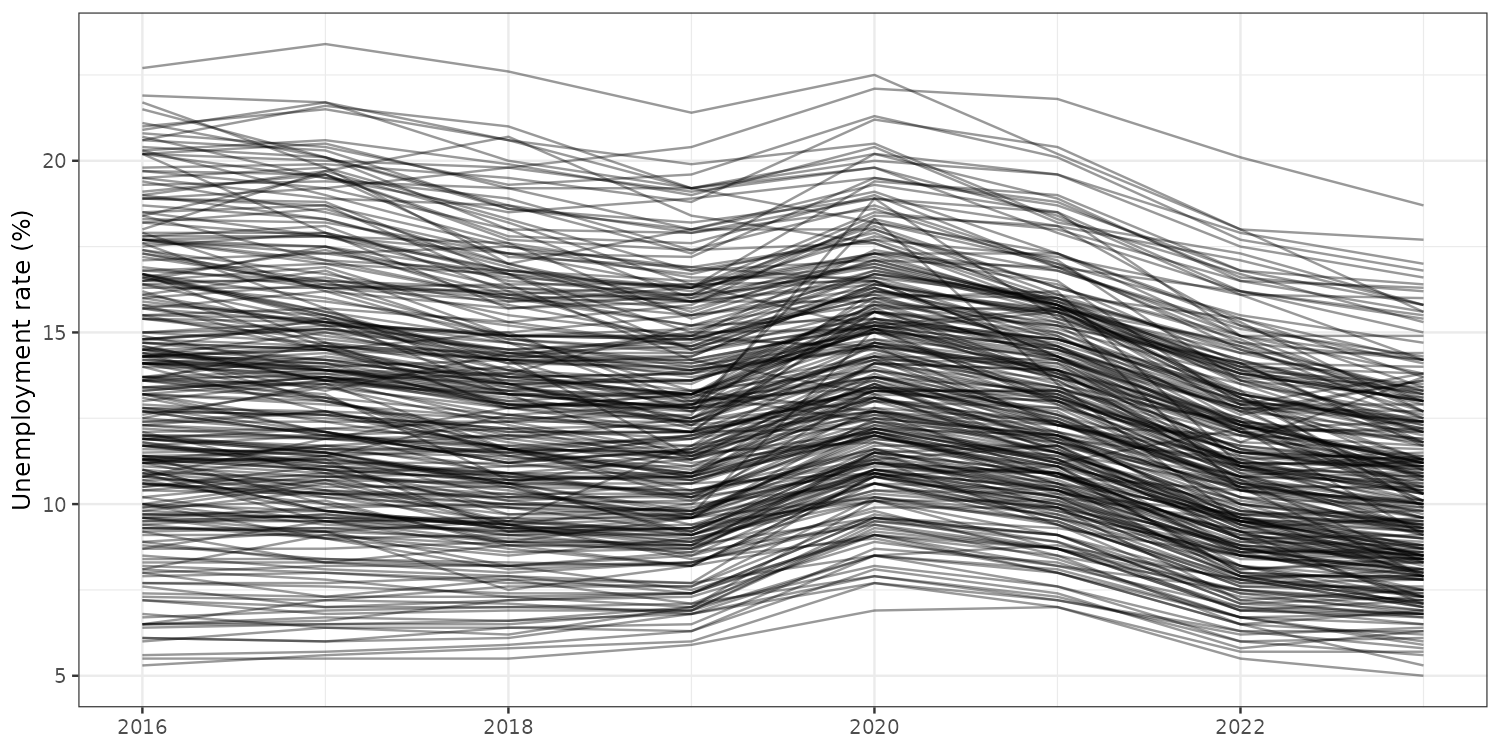
290 municipalities. You can tell rates fell, but not much else.
Same data, better figure
highlighted <- c("Danderyd", "Stockholm", "Malmö", "Pajala")
ggplot(panel_dt, aes(x = year, y = unemployment_rate, group = municipality_code)) +
geom_line(color = "grey80", linewidth = 0.4) +
geom_line(data = panel_dt[municipality_name %in% highlighted],
aes(color = municipality_name), linewidth = 1.2) +
scale_color_brewer(palette = "Dark2", name = NULL) +
labs(x = NULL, y = "Unemployment rate (%)")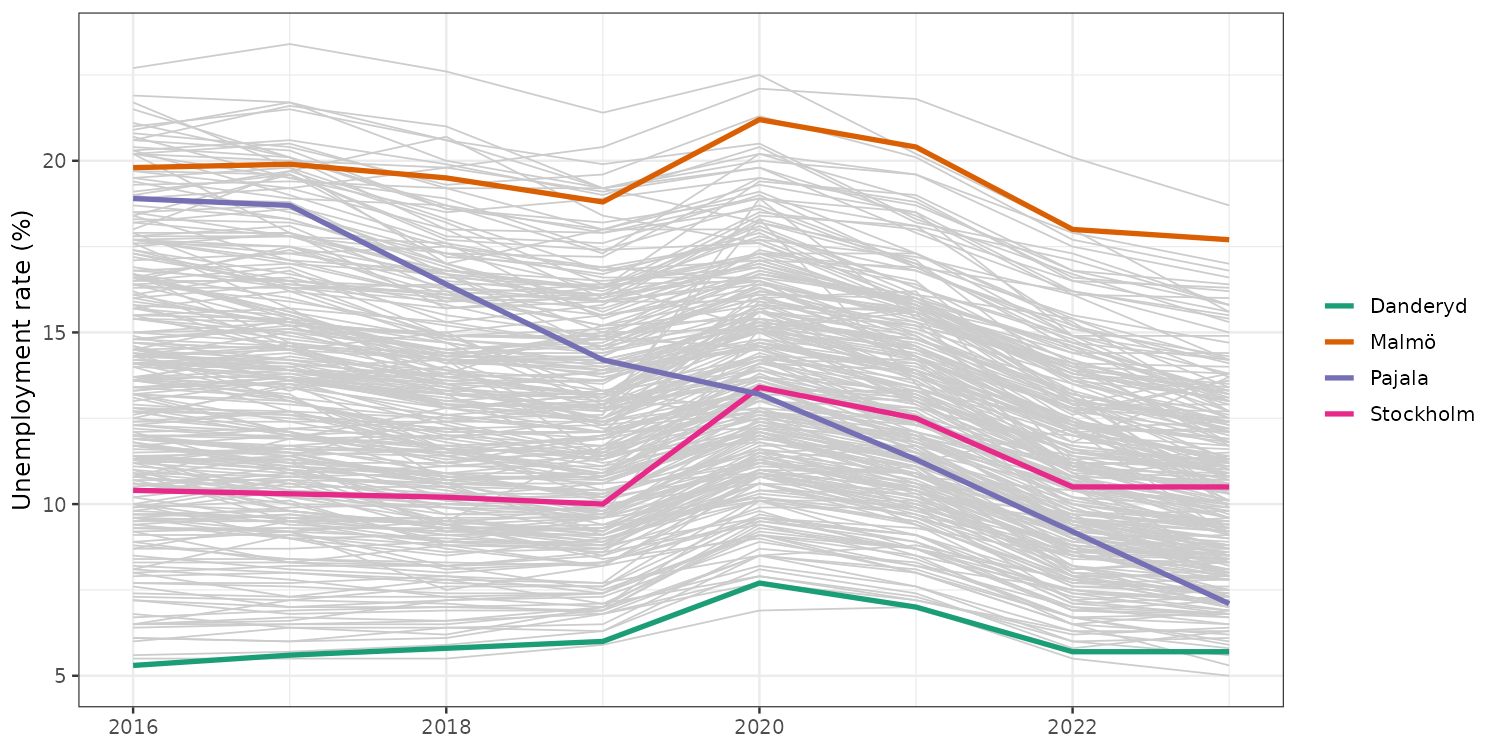
Background keeps the distribution. Foreground tells a story.
Aspect ratios and scale
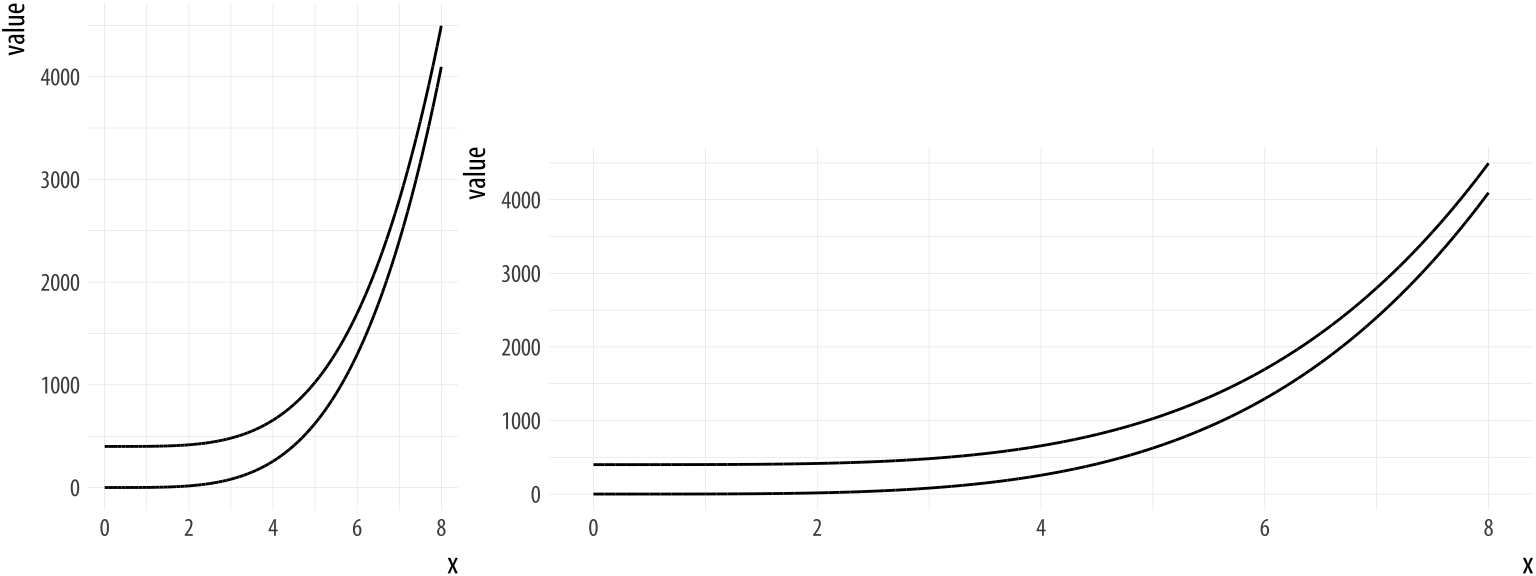
Healy (2018)
Color perception is relative
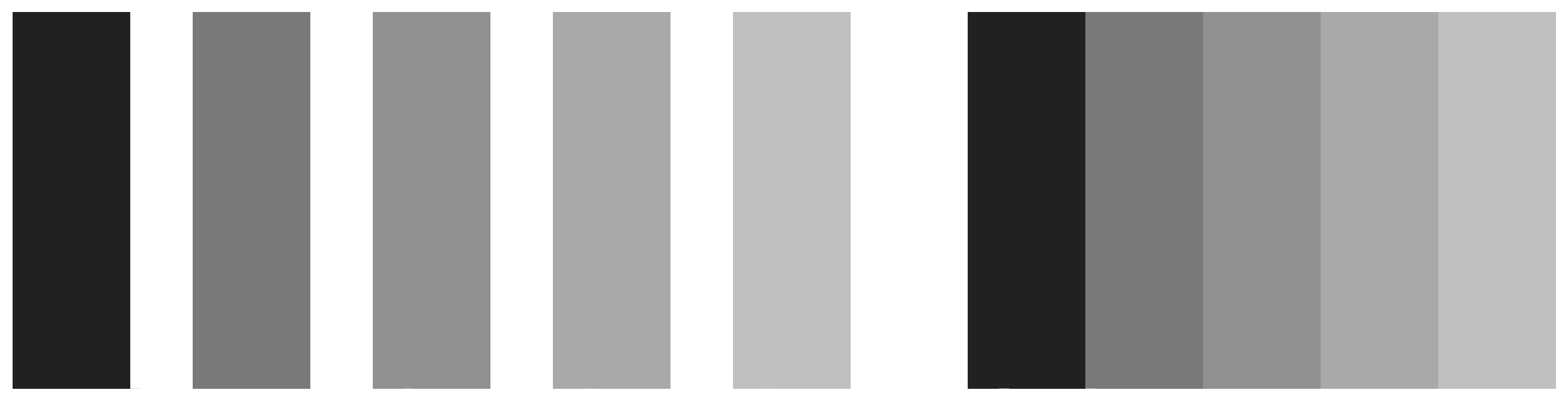
Mach bands, adapted from Healy (2018)
Creating the ggplot object (cont.)

Creating the ggplot object (cont.)
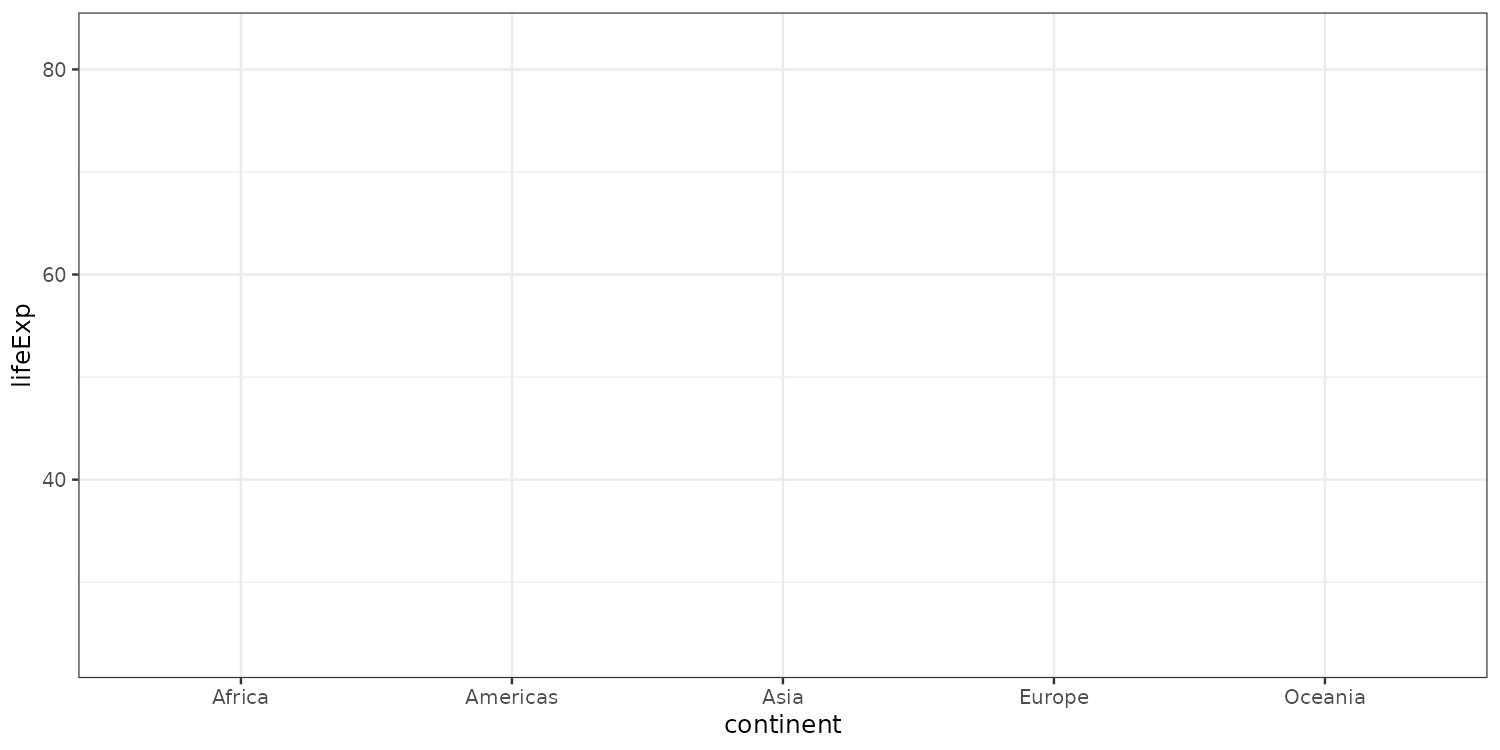
We set the aesthetic mapping of the ggplot object to columns of the gapminder data frame.
Adding a layer
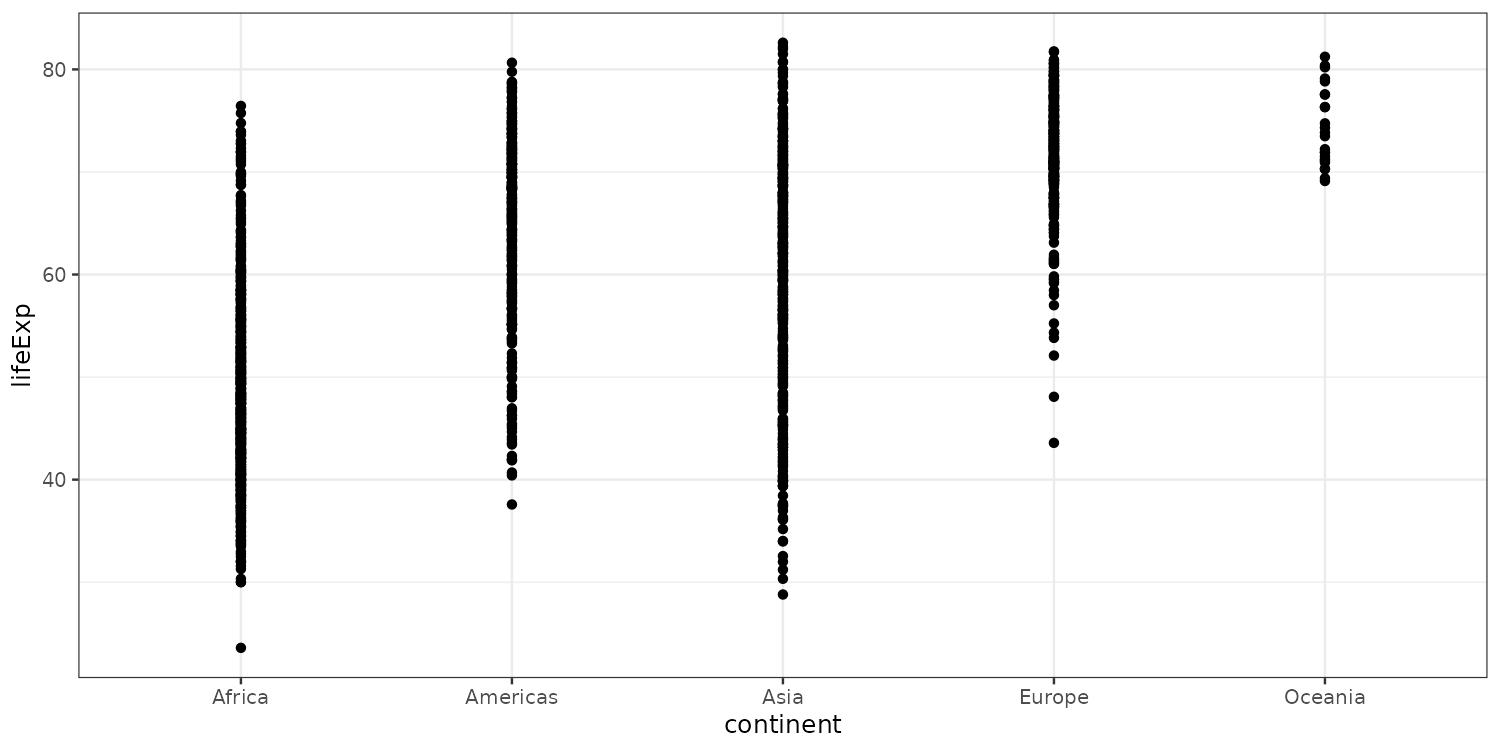
To draw something on the canvas we need to add a geometry layer. For example a scatter with geom_point().
Adding a layer (cont.)
geom_point() is a shortcut for layer(...). Setting mapping and data to NULL means they are inherited from p_box.
Adding a boxplot
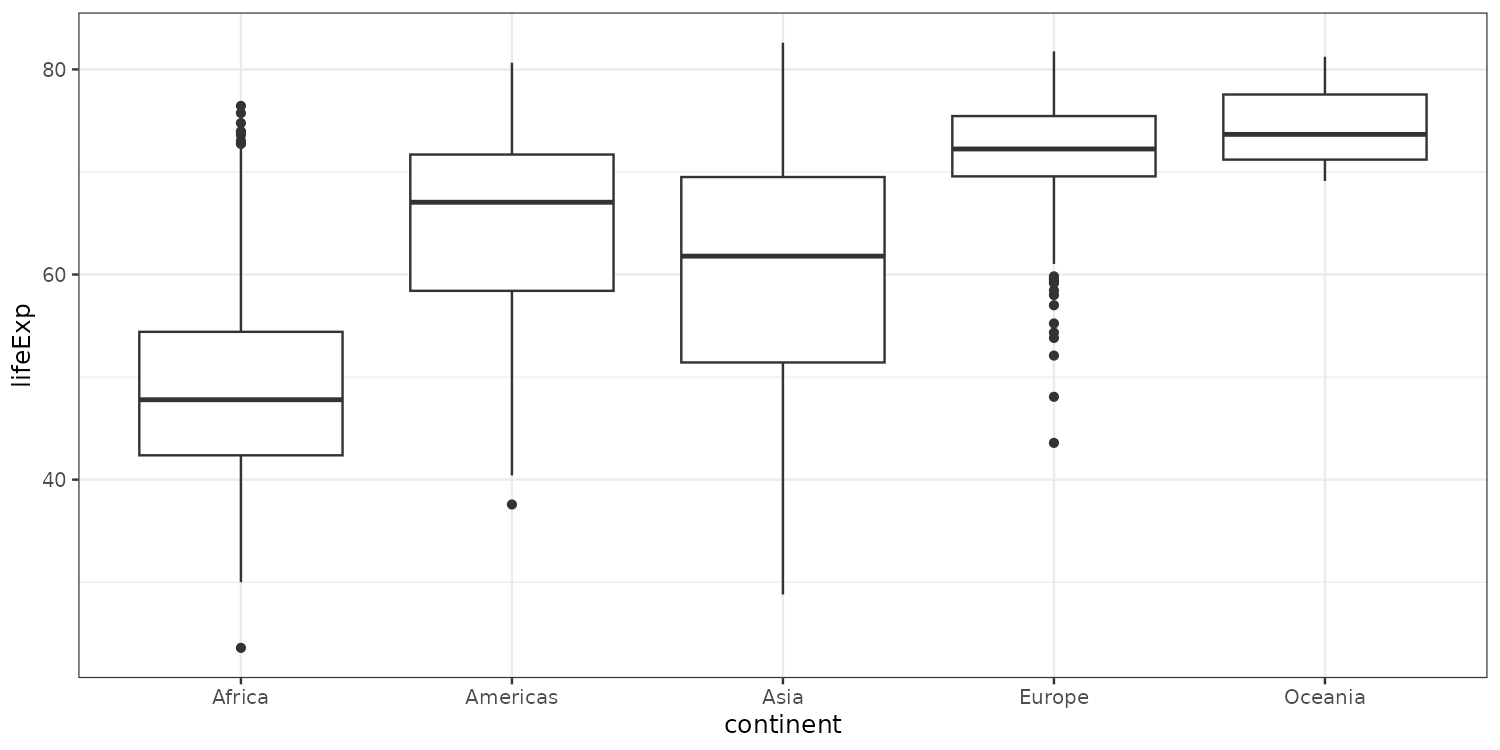
Let’s add a boxplot instead to study the distribution of continuous variables across multiple groups.
Adding another geom
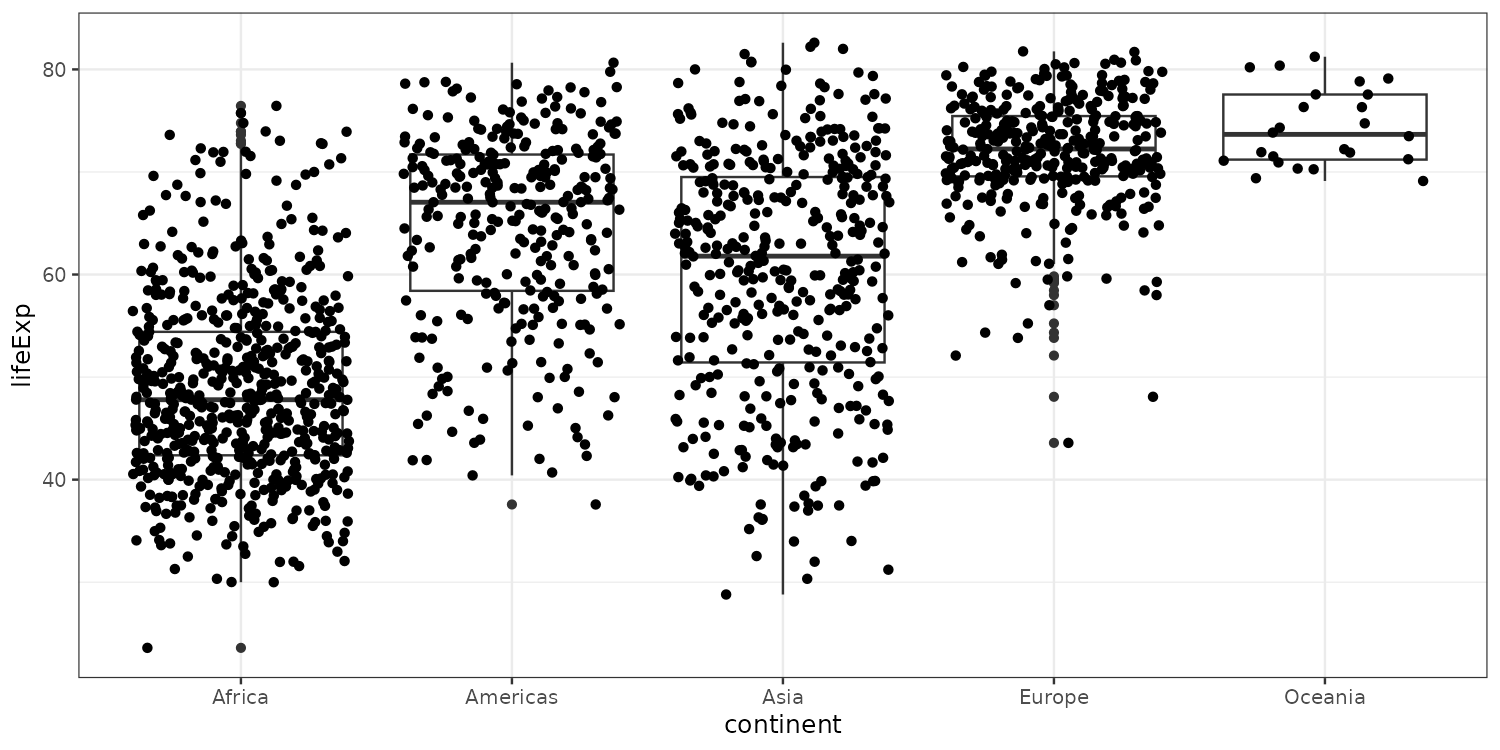
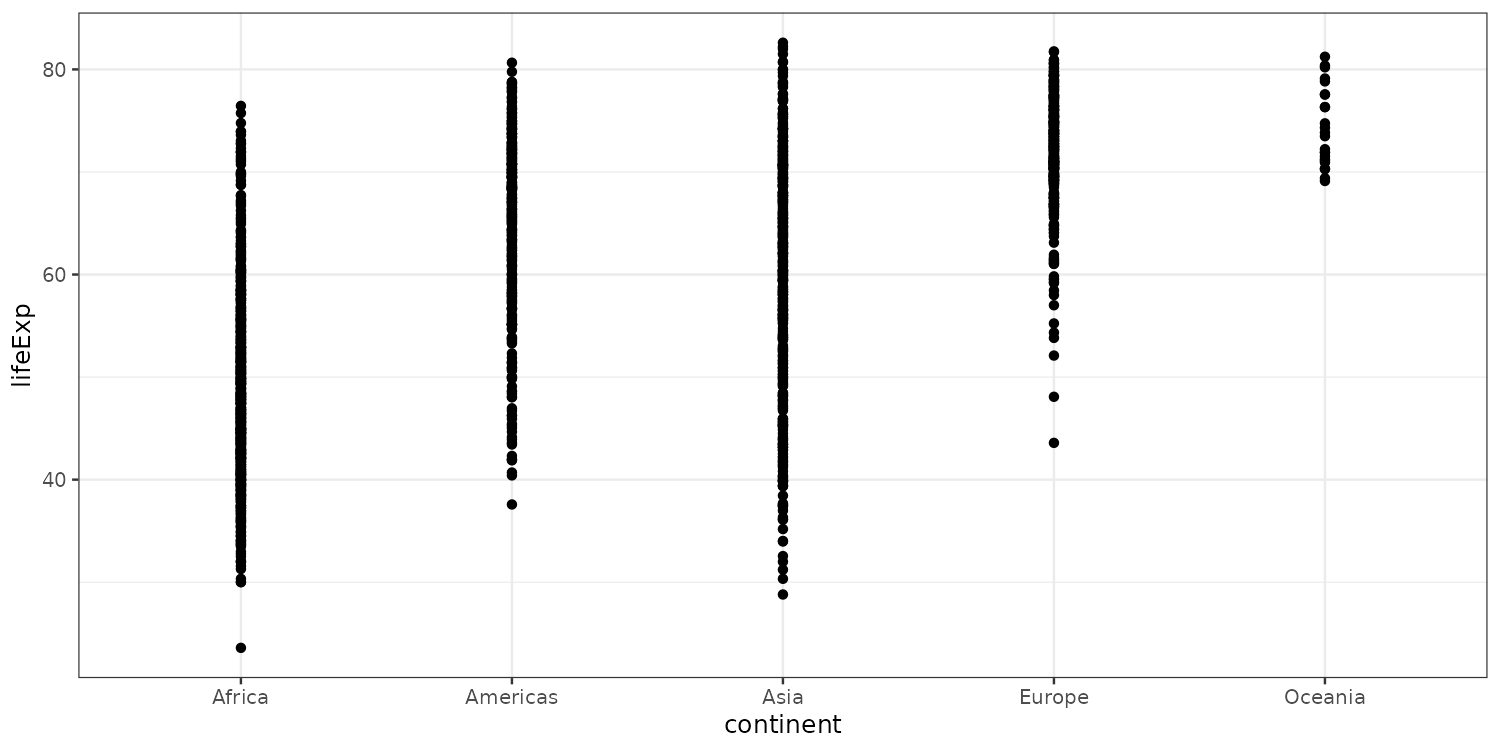
To get a more visual sense of where the data is located we can re-add the actual data points.
Styling geoms
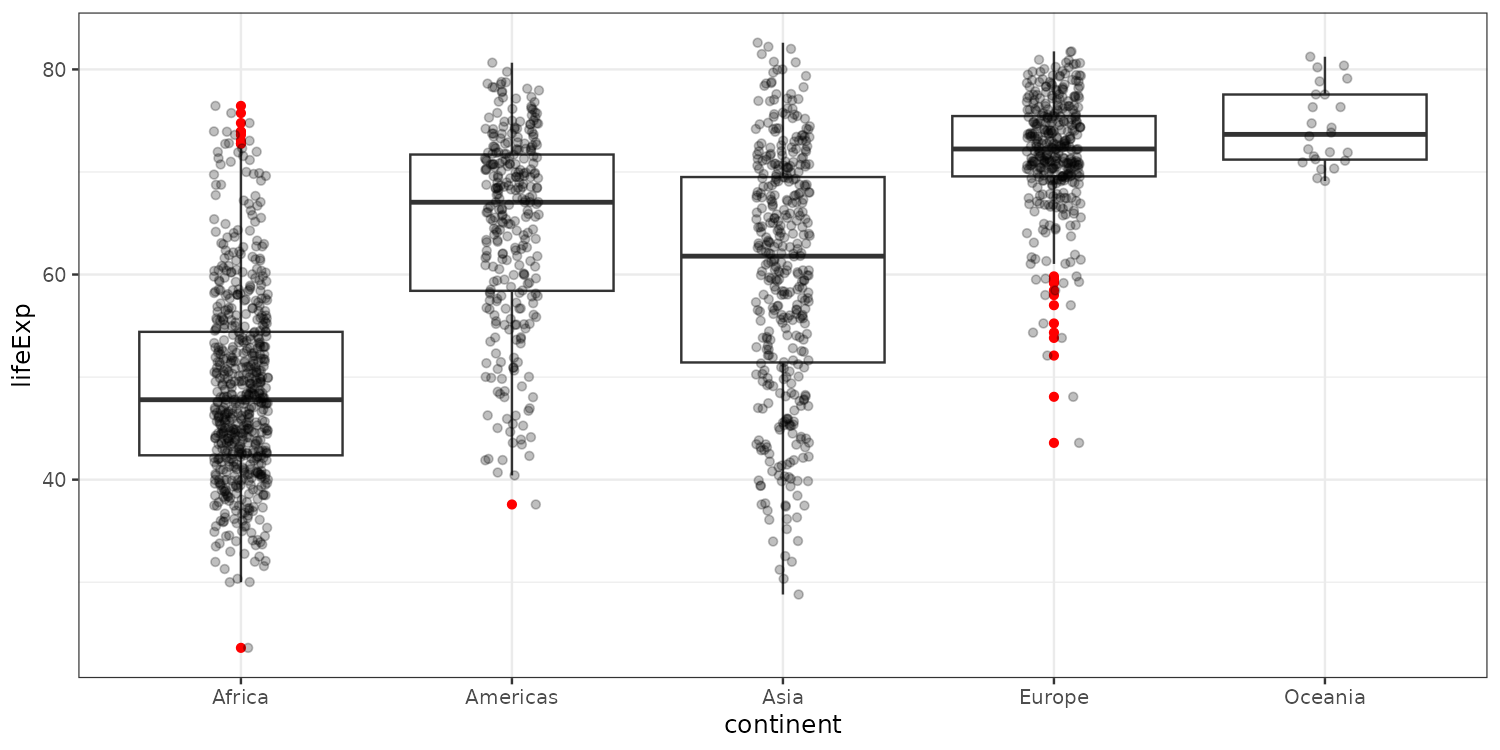
Highlighting outliers and making the points less prominent. Alpha means transparency.
Styling scales and labels
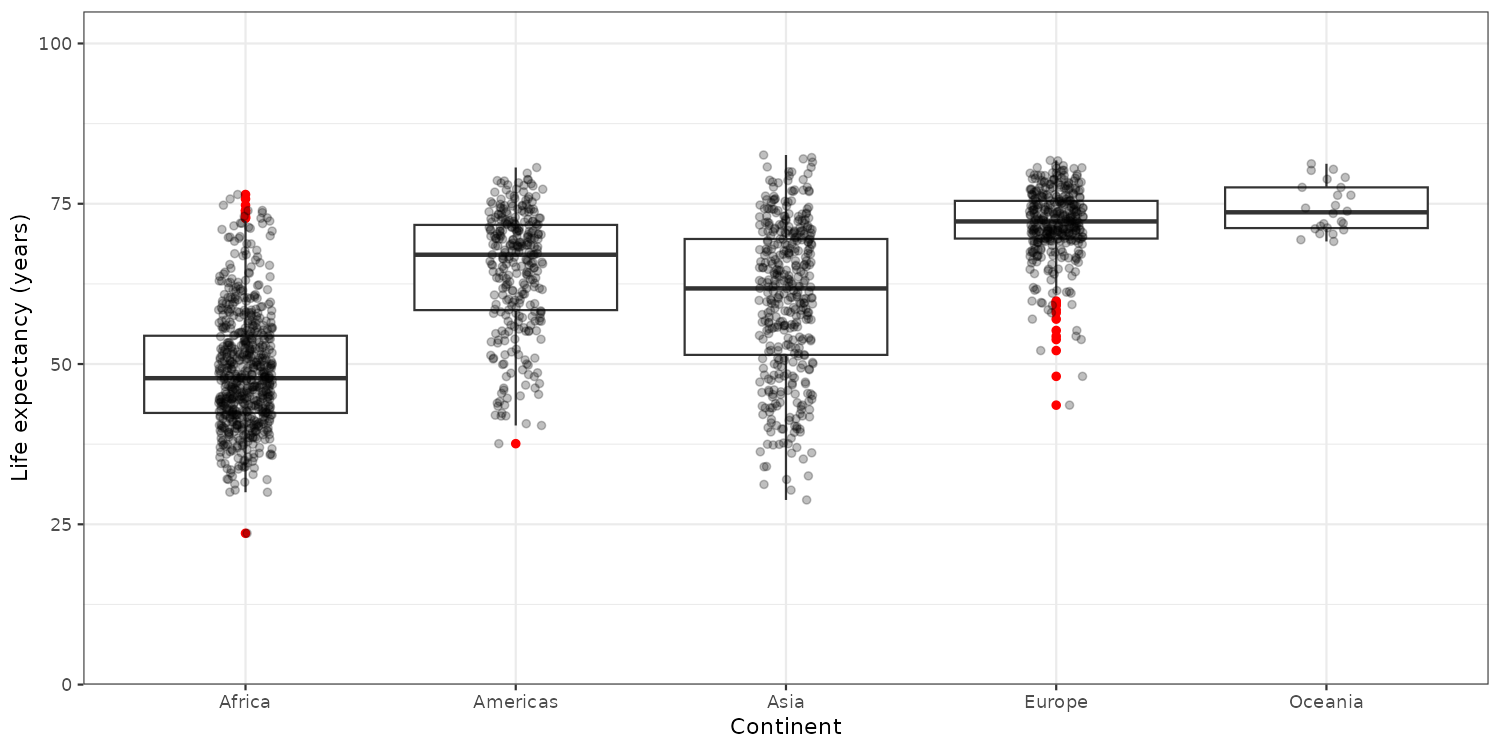
Starting the y-axis at zero usually good. Here, I also added a simple theme and formatted the axis labels.
Labelling the outliers
p_box +
geom_boxplot(outlier.color = "red") +
geom_jitter(data = plotdata[outlier == FALSE],
position = position_jitter(width = 0.1, height = 0),
alpha = 0.25) +
scale_y_continuous(n.breaks = 5,
limits = c(0, 100),
expand = expansion(c(0,0.05))) +
labs(y = "Life expectancy",
x = "Continent") +
theme_bw() +
geom_text_repel(data = unique(plotdata[outlier == TRUE], by = "country"),
aes(label = country))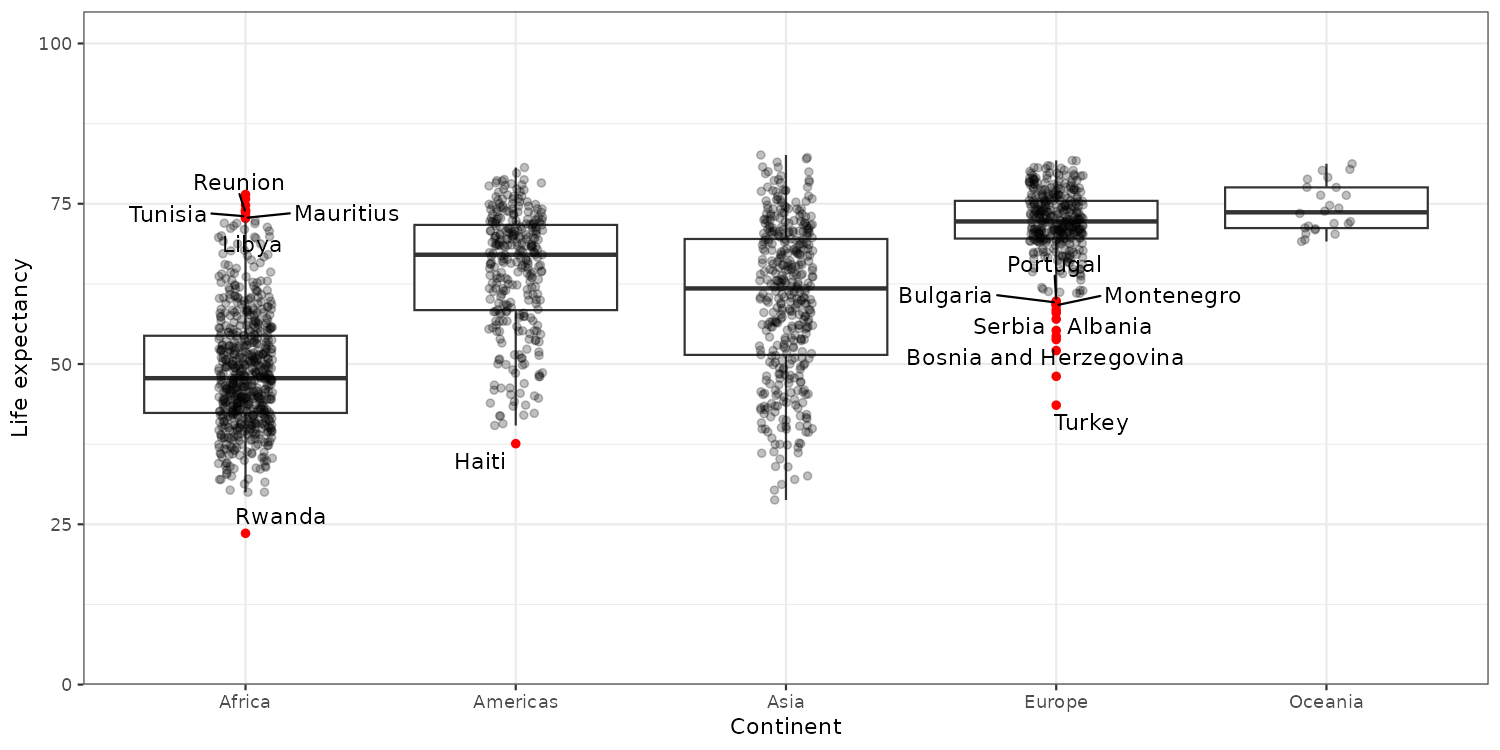
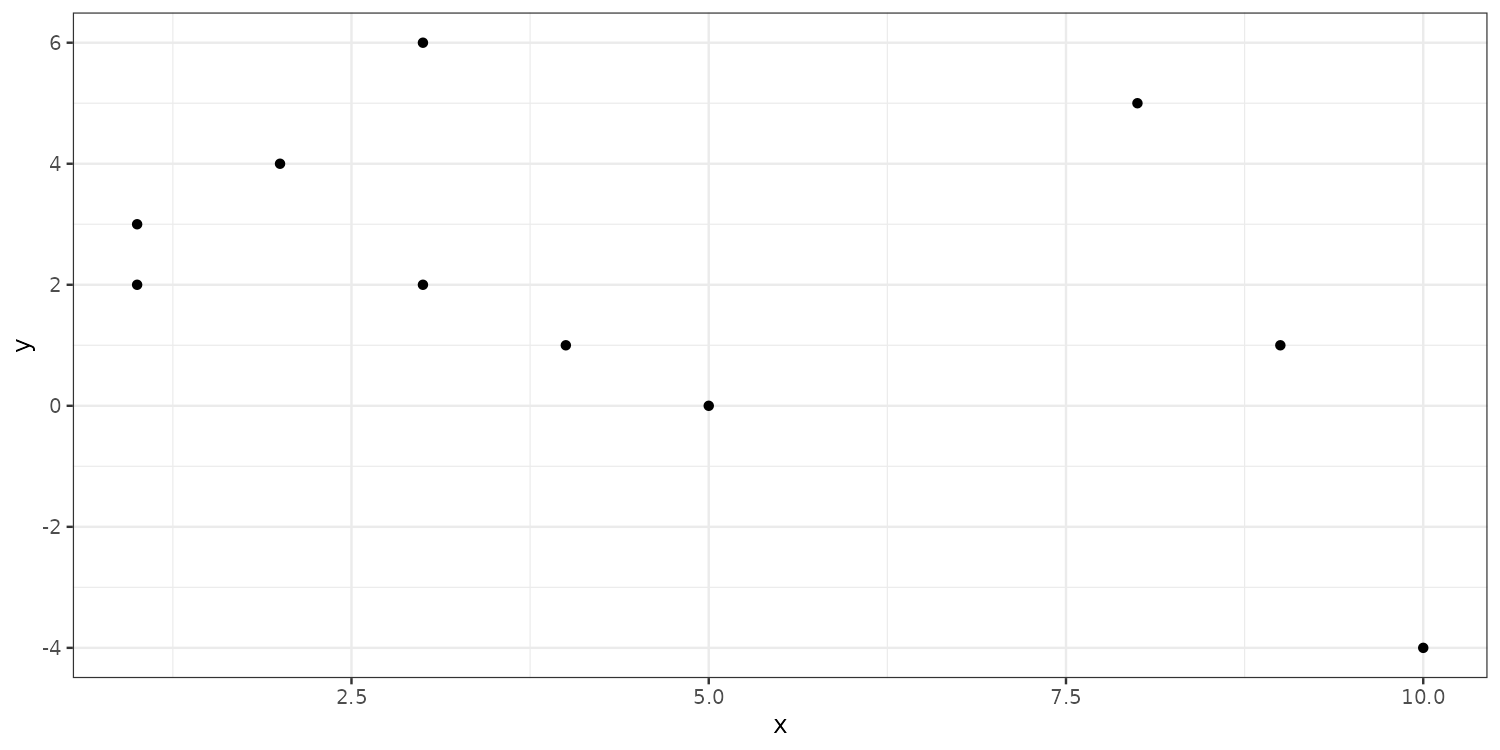
Individual geoms: geom_point()
Individual geoms: geom_col()
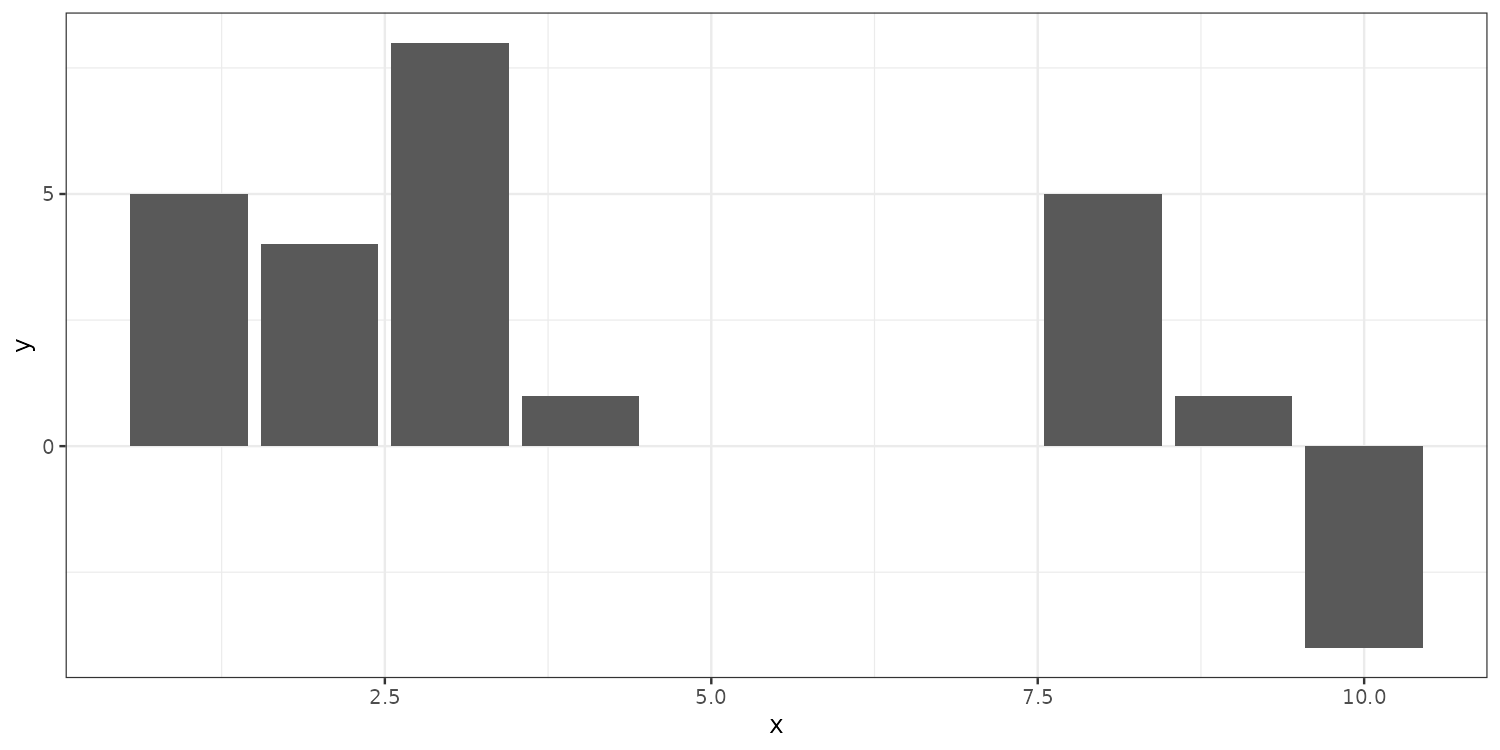
This does not look right…
Individual geoms: geom_col()
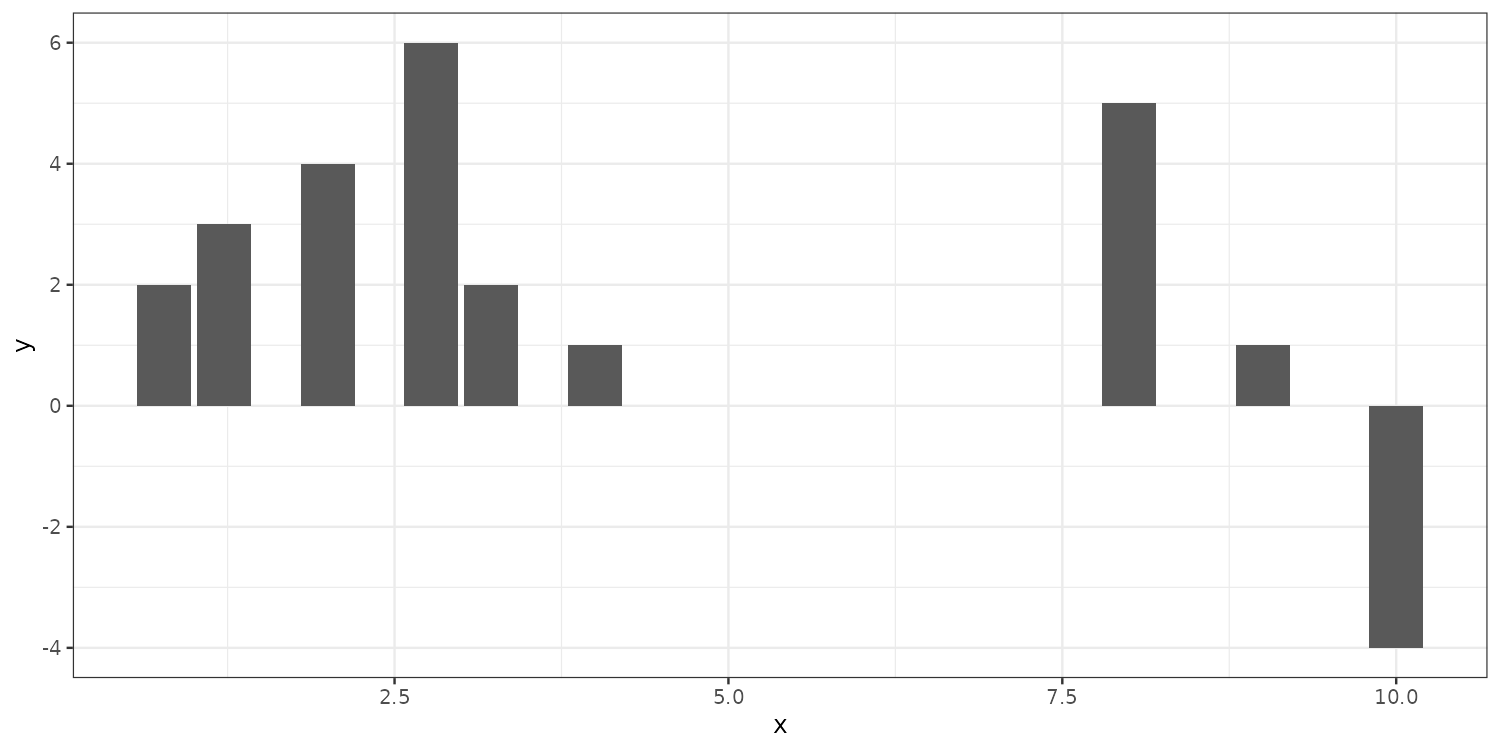
Default is position = "stack", this puts same x values on top of each other. Setting it to dodge separates overlapping values.
Collective geoms
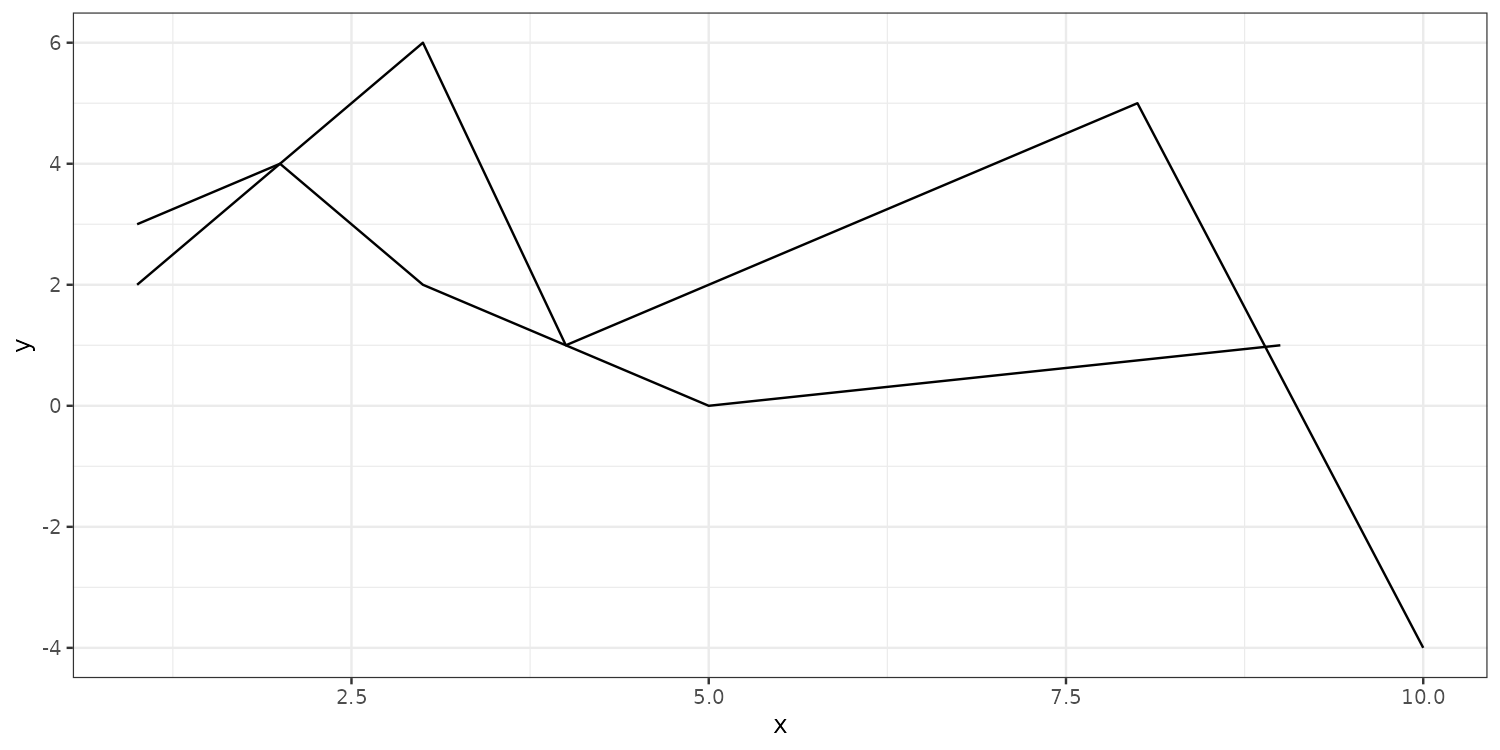
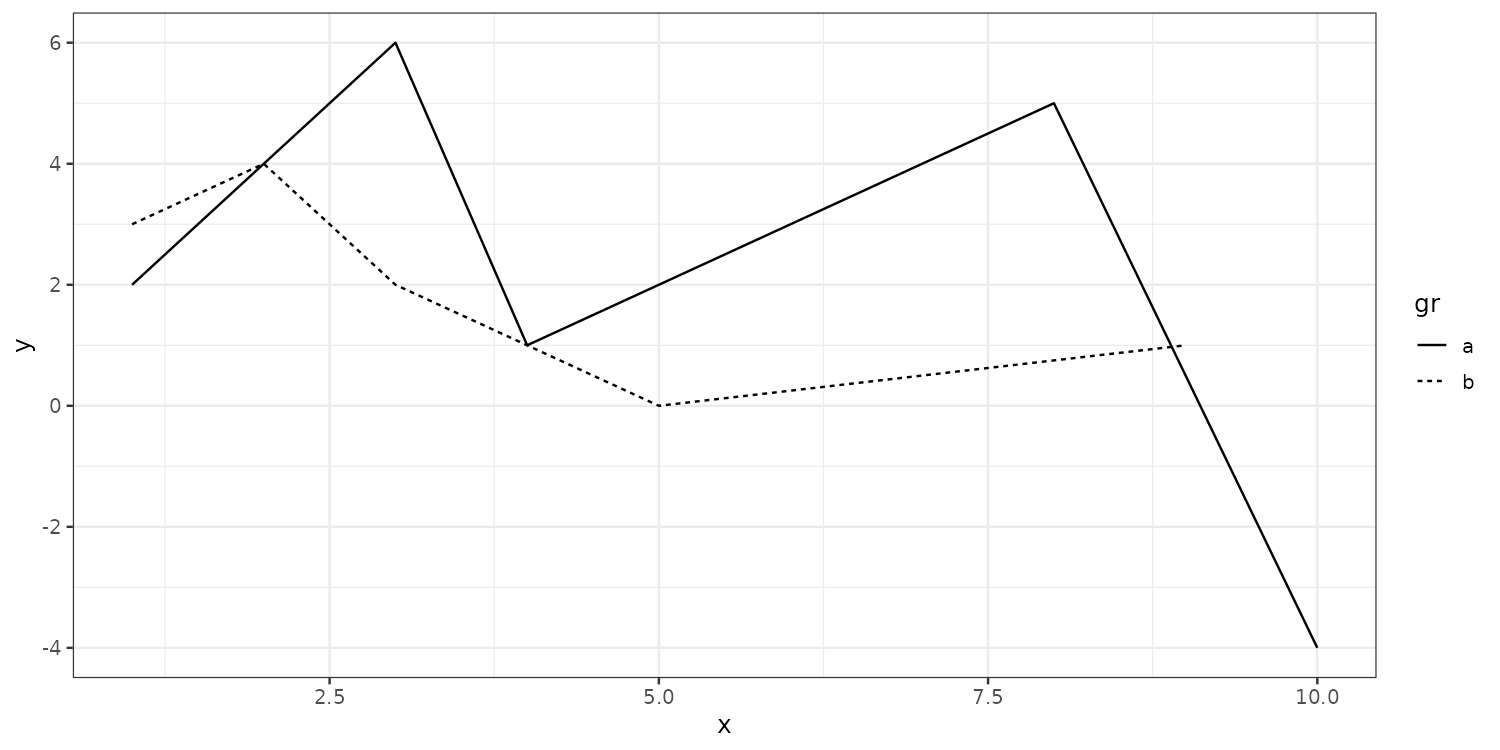
Collective geoms are plots with connected observations. group tells ggplot how to connect the data.
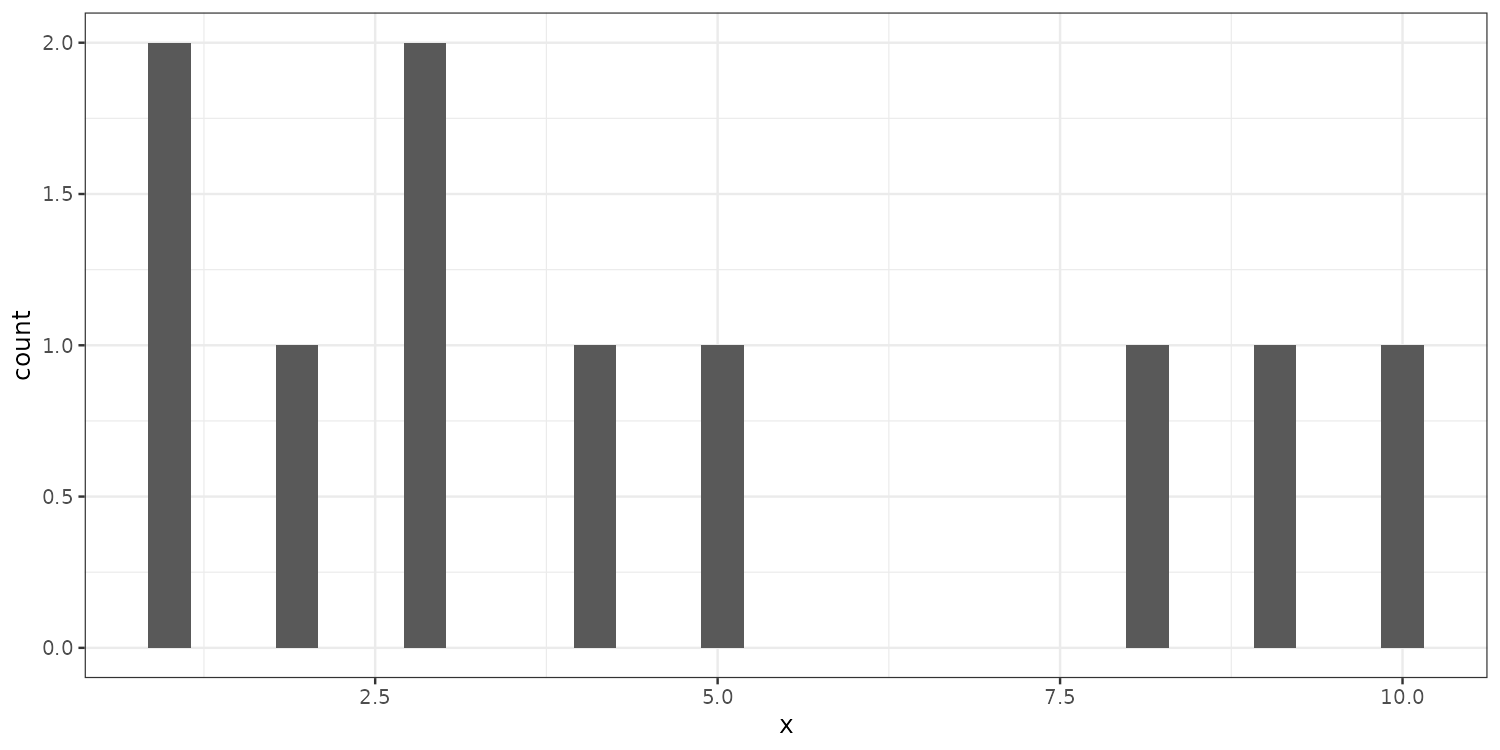
Statistical summaries: geom_histogram()
Statistical summaries: geom_smooth()
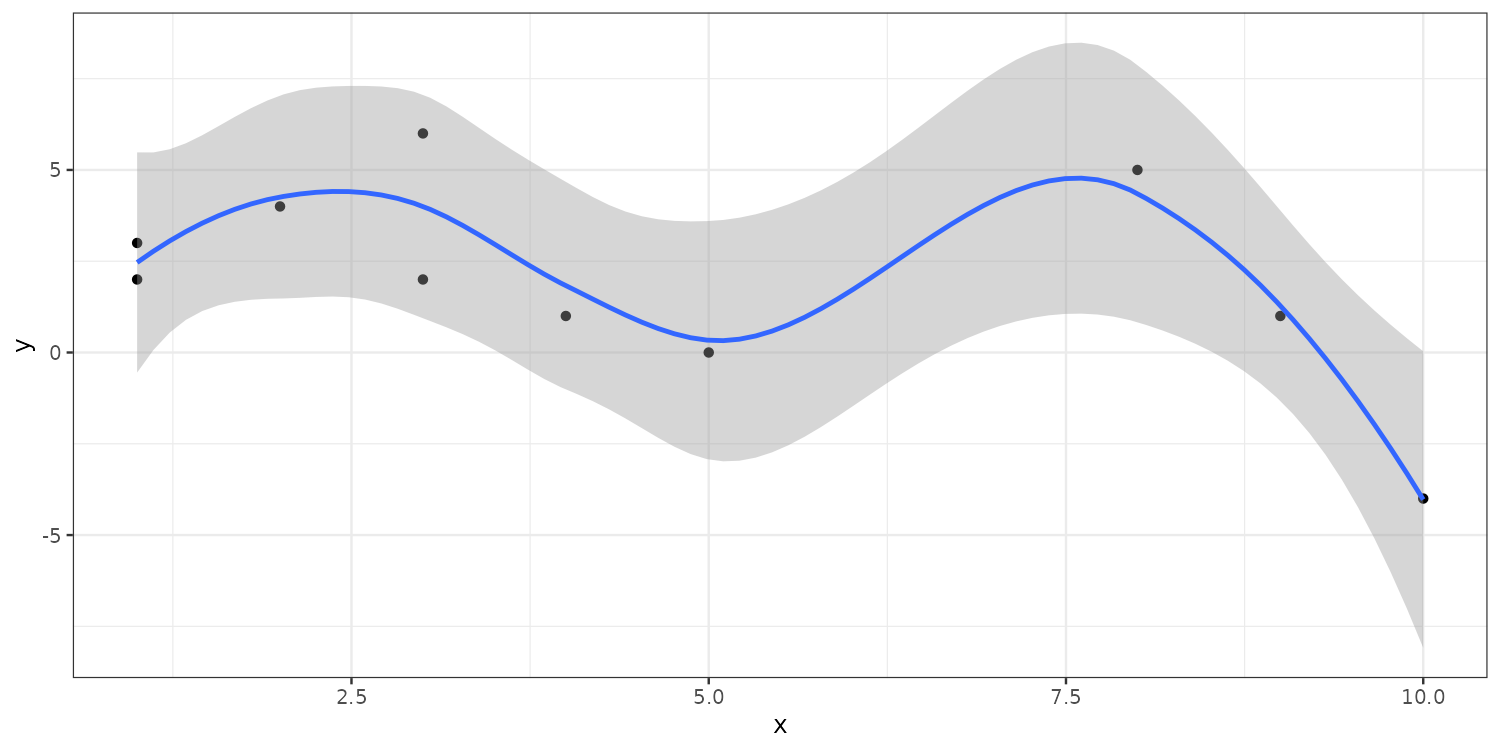
By default geom_smooth() fits a loess curve. Pass method = "lm" for a straight line.
Statistical summaries: geom_errorbar()
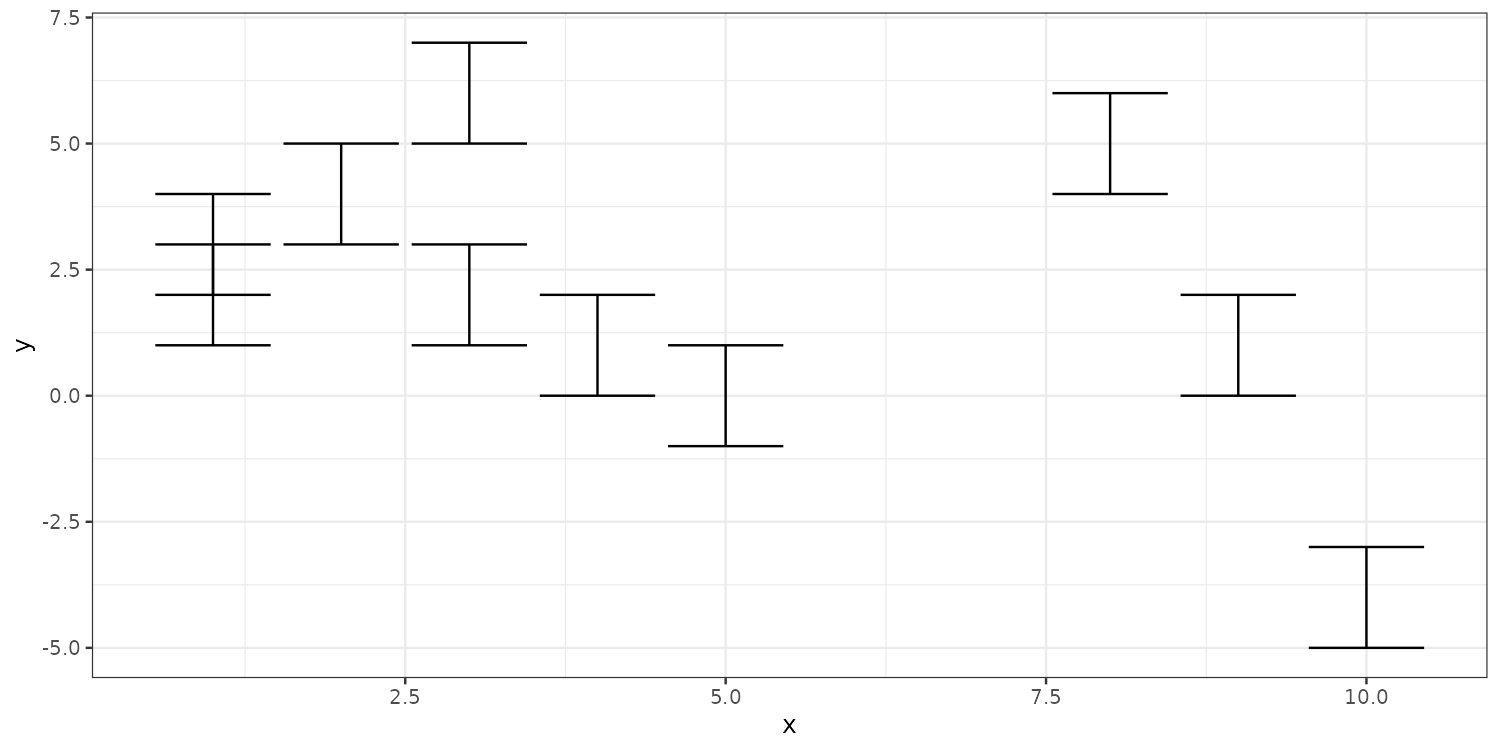
Useful for reporting e.g., coefficient plots, but requires ymin and ymax aesthetics.
Grouping and summarizing
What if we wanted to plot how GDP per capita has developed for each country over time. A line plot should do this well.
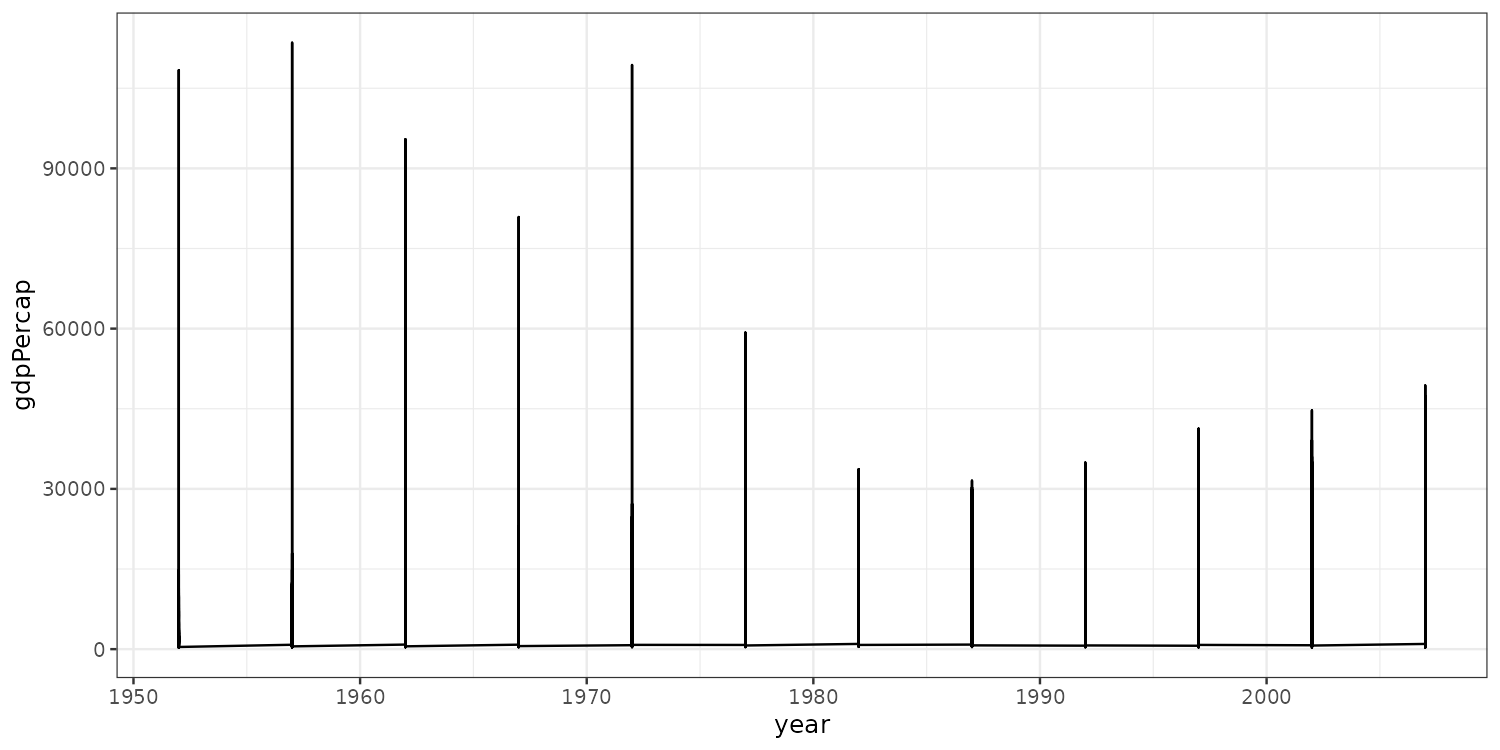
Any idea what’s wrong?
The group aesthetic
We need to tell ggplot to group the data by country.
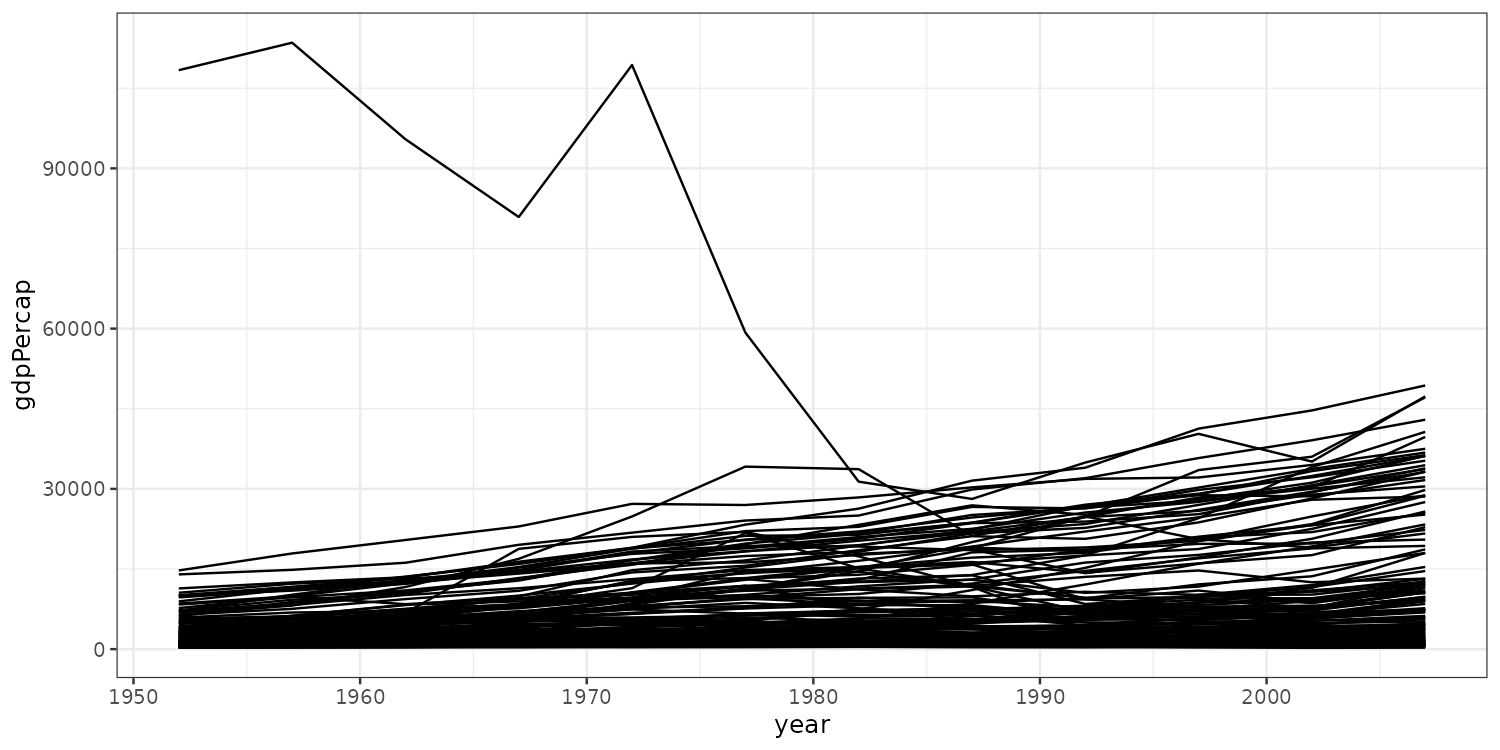
Still quite hard to see what’s going on!
Making things clearer
Let’s color lines by continent.
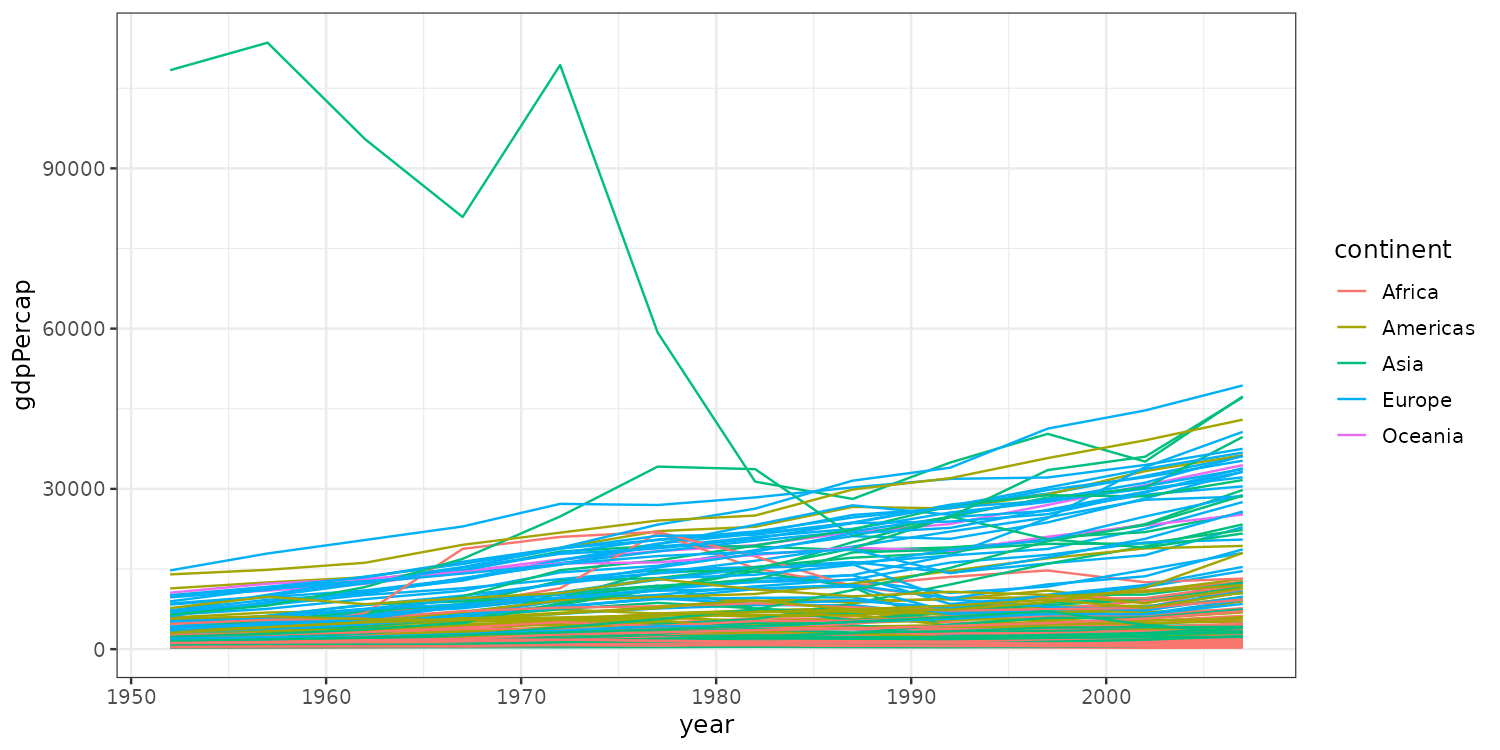
Still looks cluttered.
Faceting
Instead we could split the plot into subplots by continent.
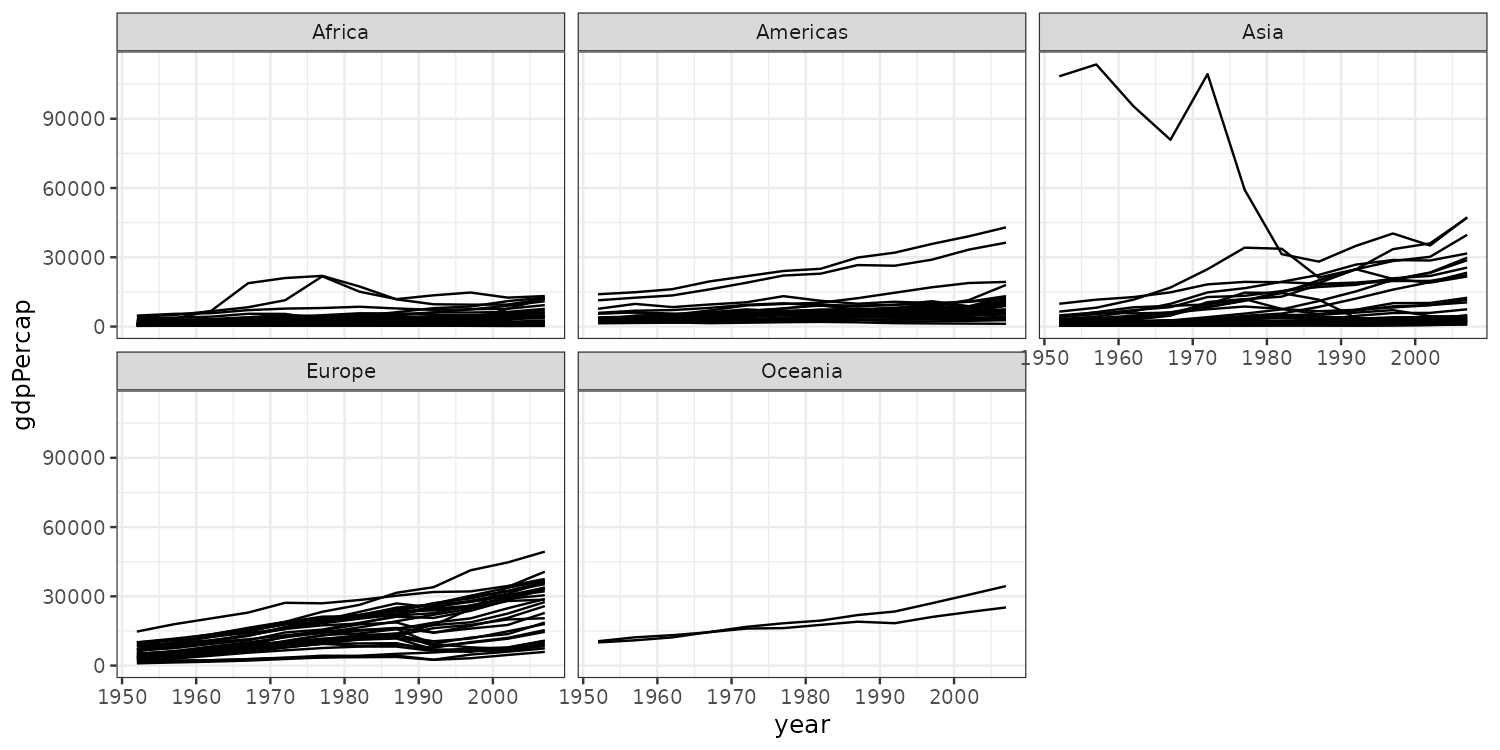
By default facet_wrap() keeps the x and y scales identical across panels. Pass scales = "free_y", "free_x", or "free" to let them vary.
A plot to work on
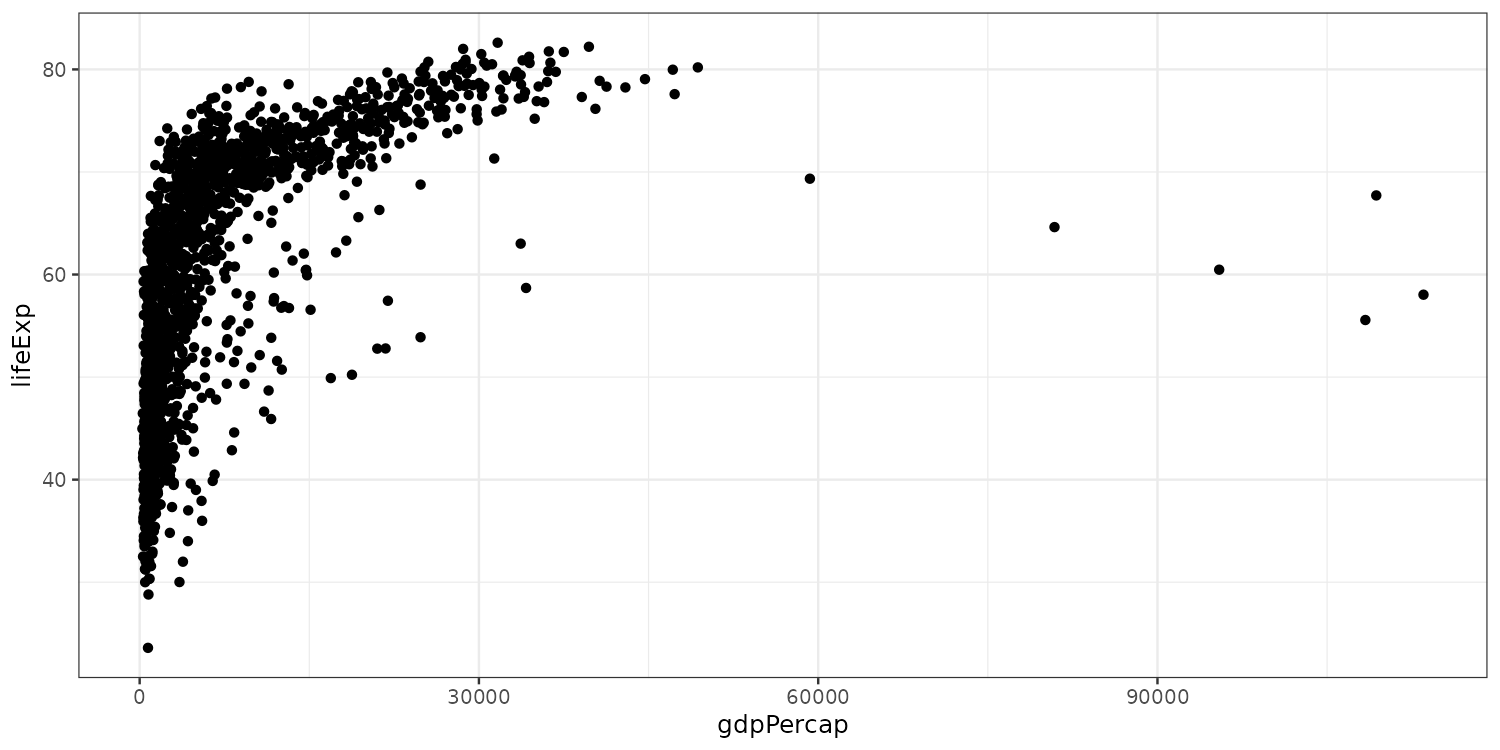
How can we increase readability?
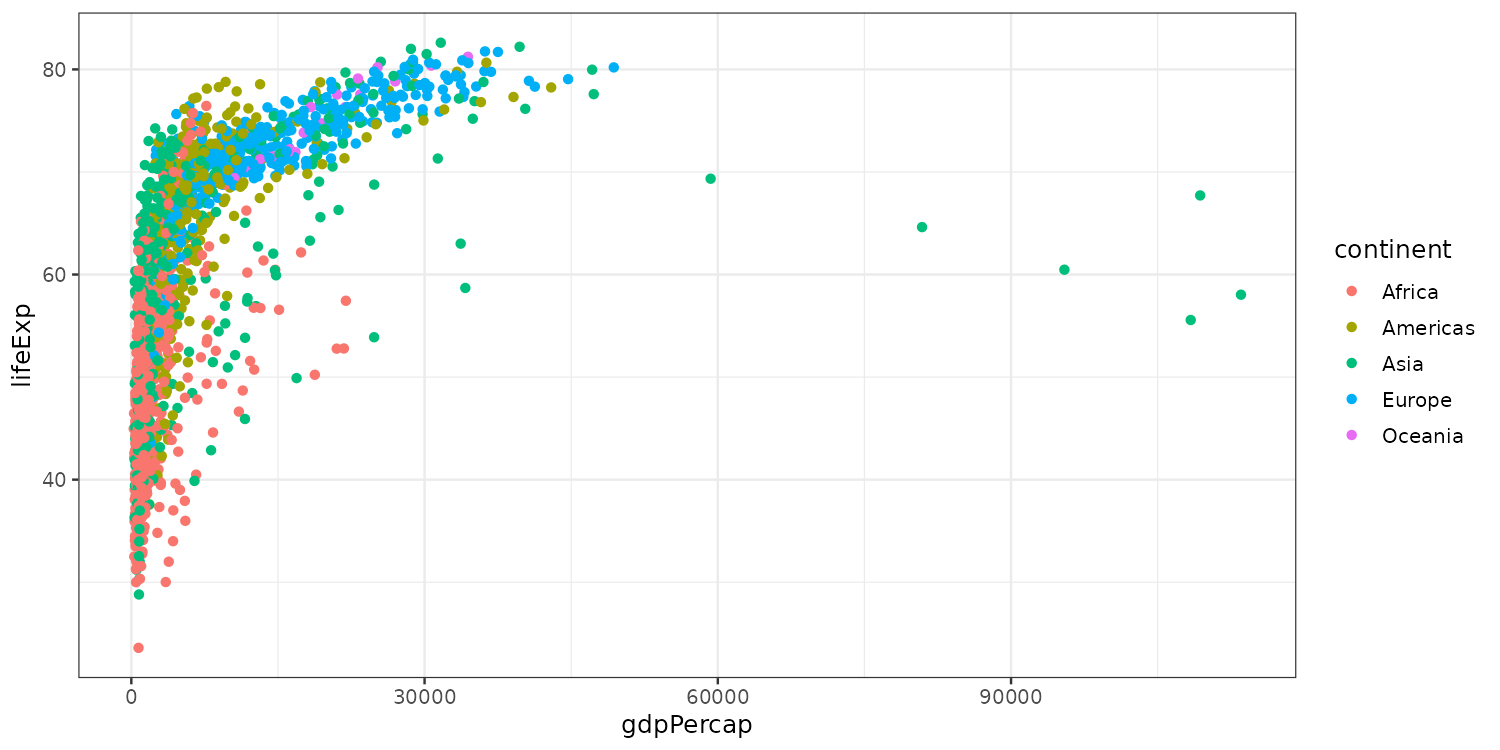
Configuring scales: color
Configuring scales: size
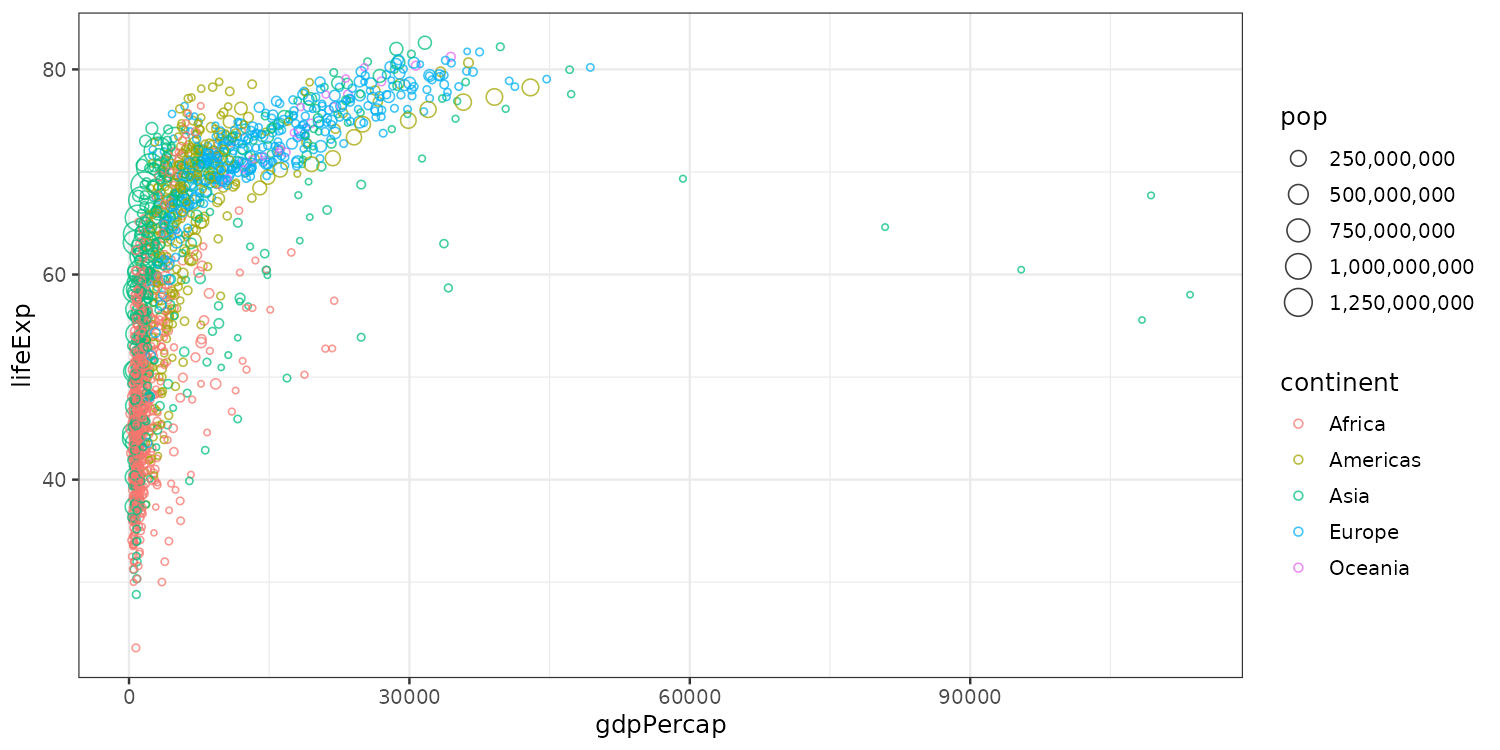
- Makes point size vary with population size,
- with semi-transparent hollow circles
- Change size scale to non-scientific
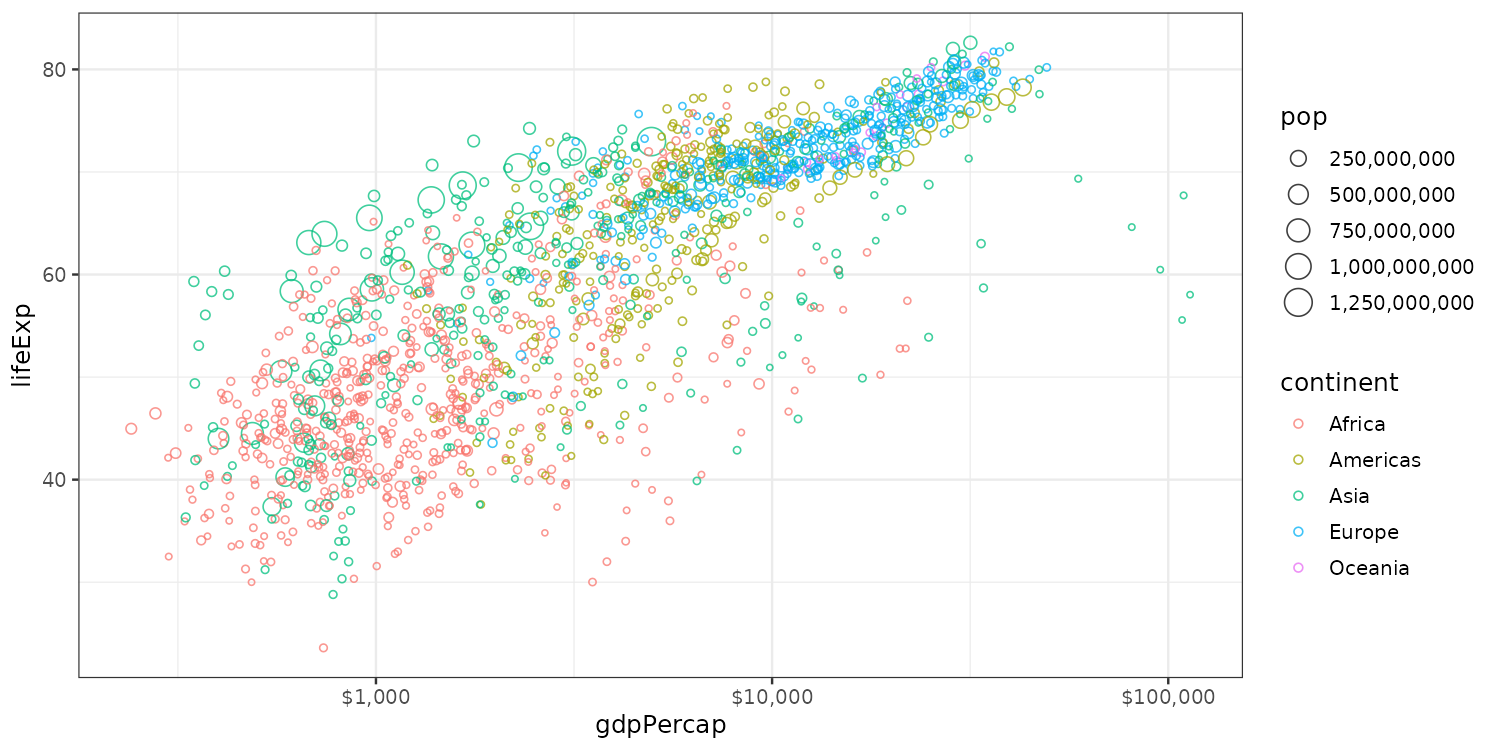
Configuring scales: logarithmic x-scale
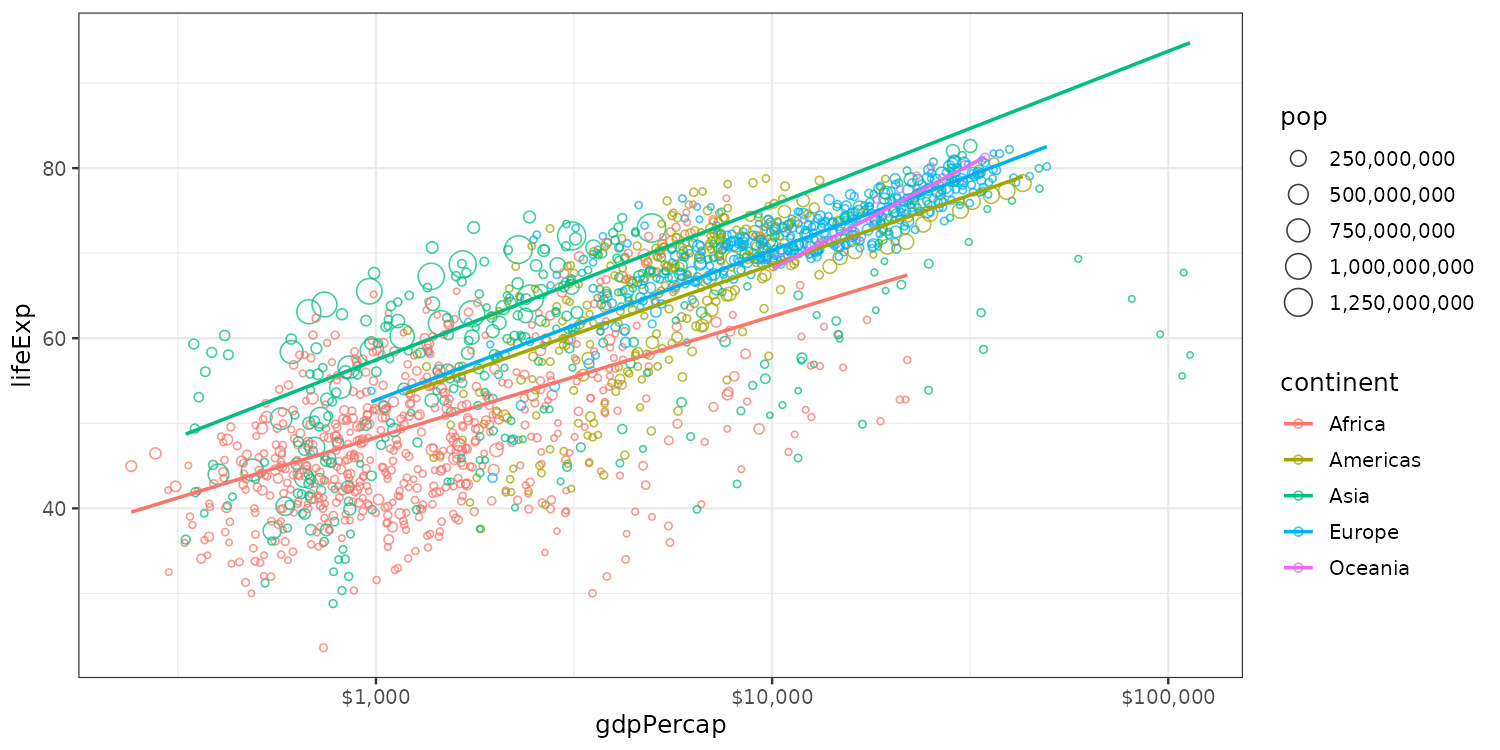
Adding (population weighted) regression lines
Adding plot labels
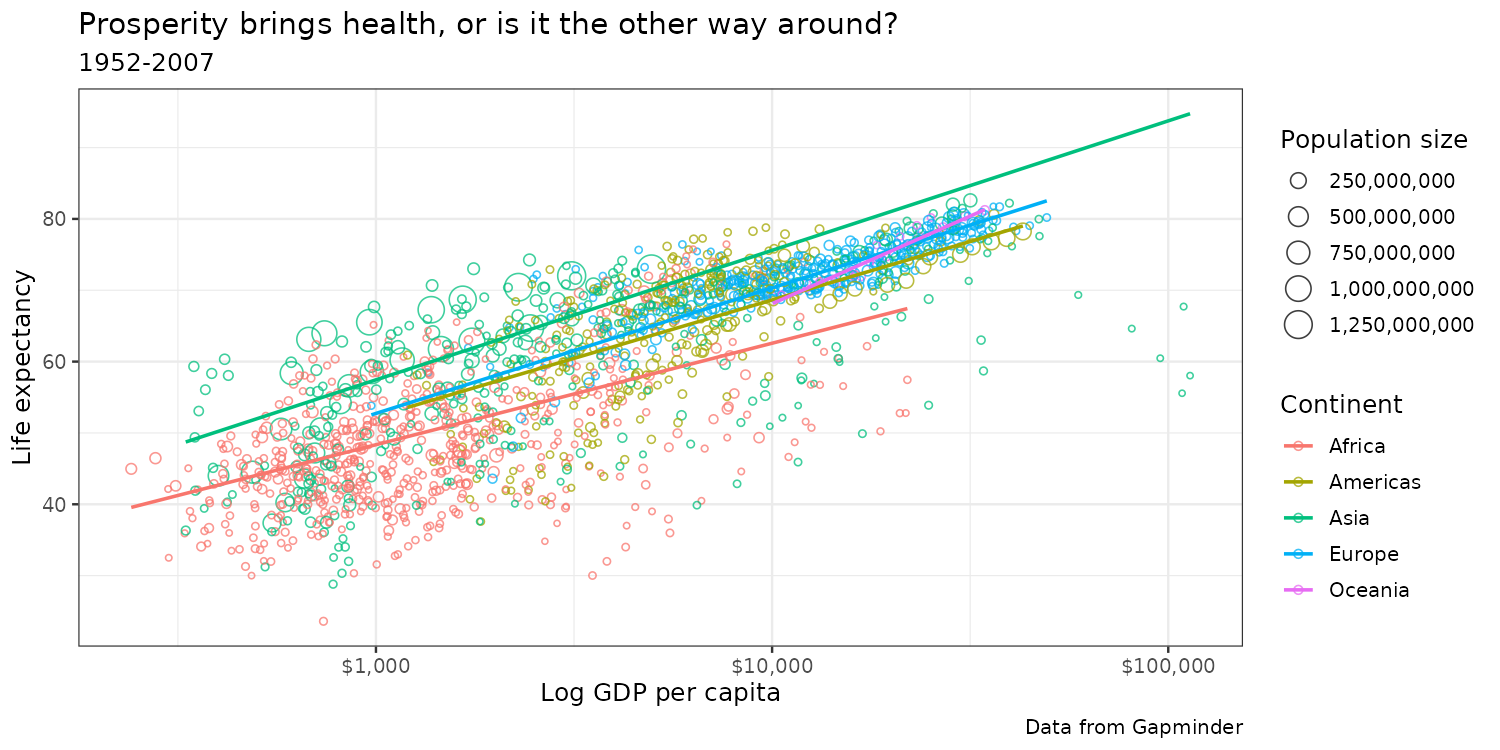
theme() sets look and feel
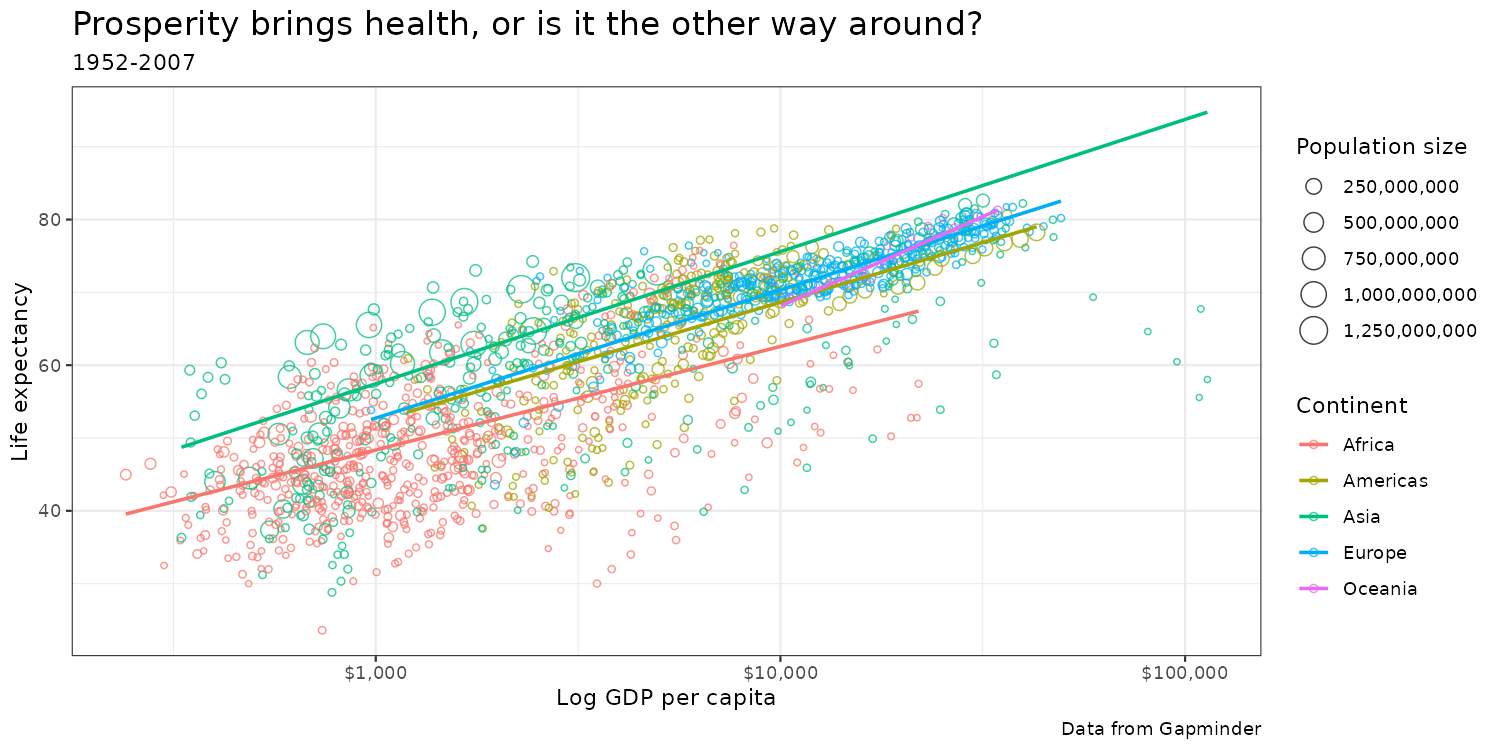
Color blindness: ggplot2 default hue

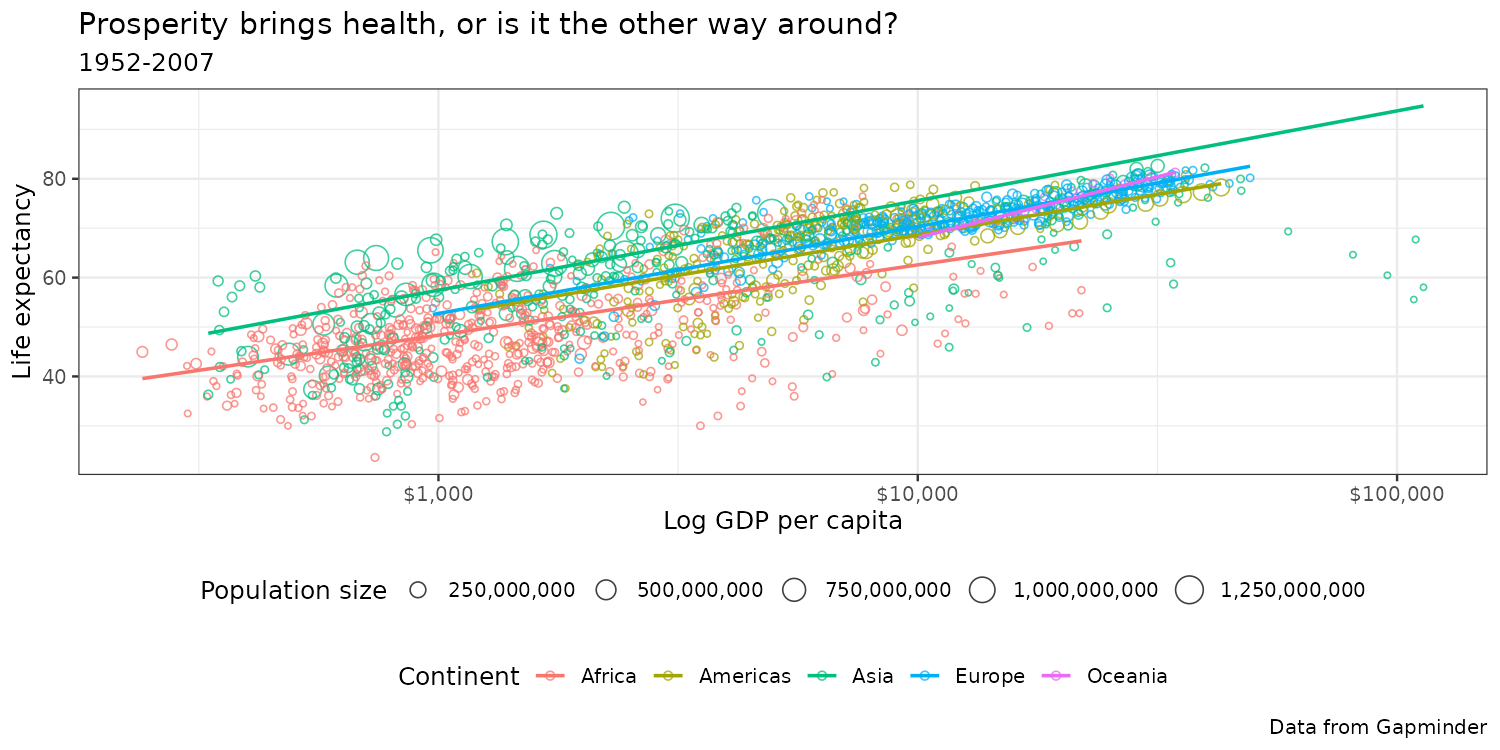
Color blindness: RColorBrewer RdYlGn

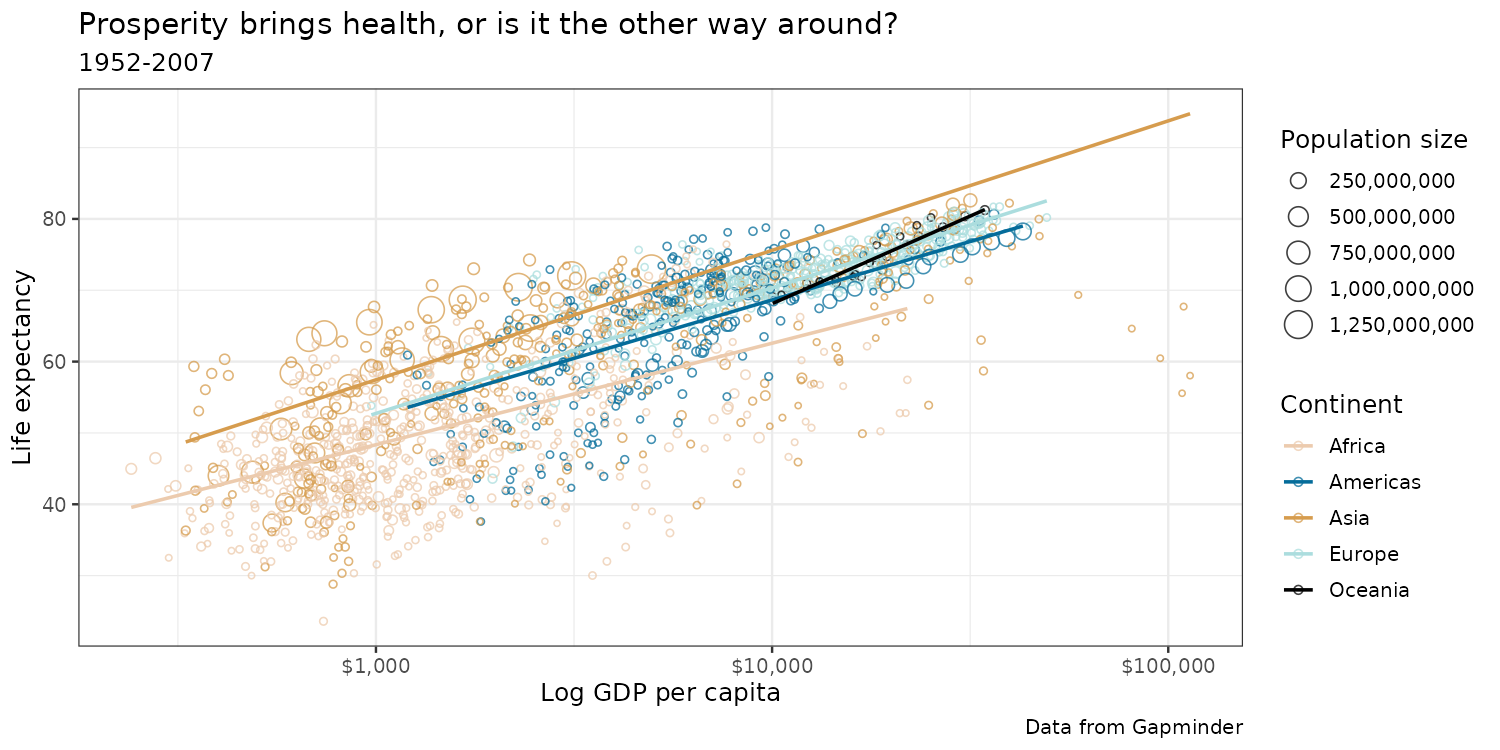
Color blindness: Wes Anderson Darjeeling 2

Let’s go with this one for our plot!
Final result
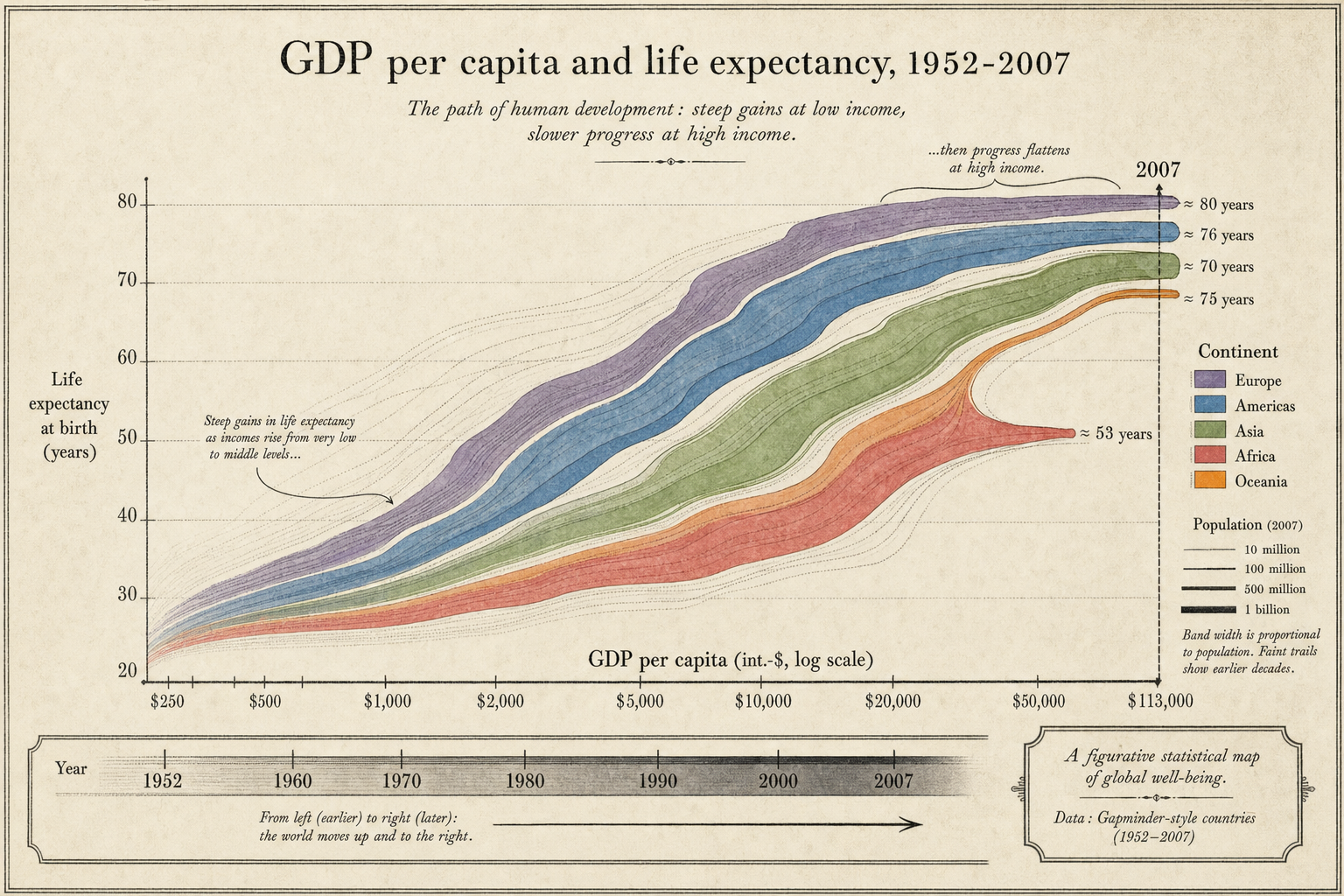
LLMs as plot generators
Course arc, looking back

- Every block has the same shape: real data, a small toolkit, a validation step
- The tools will keep changing; the workflow shape does not